Tab Mapper
The tab mapper is a handy little tool that will render a guitar tab file with graphic chord diagrams displayed alongside. This comes in handy for people who just don't have every single chord shape memorized. Just plug in the web site address of a valid .tab or .crd file and hit "Go". In general, the tab mapper does a better job with printer friendly URLs. If there is more than one way to play a chord, the tab mapper will choose the most common shape. To see other fingerings, click on the chord diagram and you will be taken to the chord calculator.
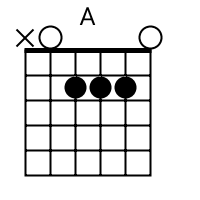
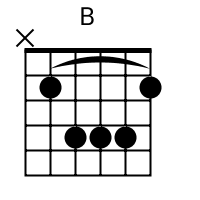
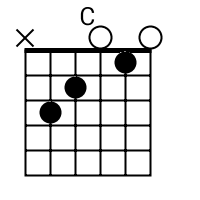
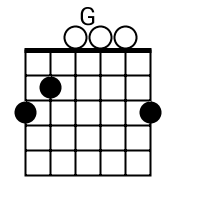
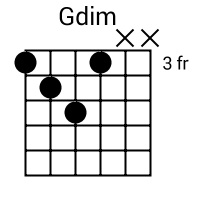
Original file located @ http://cassavabase.org.
Show me scales that sound good with the chords in this song: A, B, C, G, Go, AM.
Old browser version detected
This site is optimized for modern web browsers
Sorry!, some features may not work in outdated browsers
- Search
- Wizard
- Accessions and Plots
- Organisms
- Progenies and Crosses
- Field Trials
- Genotyping Plates
- Genotyping Data Projects
- Genotyping Protocols
- Accessions Using Genotypes
- Traits
- Images
- People
- FAQ
- Manage
- User Roles
- Breeding Programs
- Locations
- Accessions
- Seed Lots
- Crosses
- Field Trials
- Genotyping Projects
- Tissue Samples
- Field Book App
- Phenotyping
- Barcodes
- Label Designer
- NIRS
- Markerset
- Download
- Upload
- Identifier Generation
- Drone Imagery
- Genotyping QC
- Analyze
- Quality Control
- Validated Trials
- Analyses & Models
- Breeder Tools
- Selection Index
- Genomic Selection (solGS)
- Genomic Prediction of Parent Combinations
- Population Structure (PCA)
- Clustering
- Kinship & Inbreeding
- Correlation
- Stability AMMI/GGE
- Heritability
- Accession Usage
- Mixed Models
- Compare Trials
- Graphical Filtering
- BoxPlotter Tool
- GWAS
- Image Analysis
- Sequence Analysis
- BLAST
- VIGS Tool
- HapMap Jbrowse
- Other
- Ontology Browser
- Compose a New Trait
- SOPs
- IITA Hybridization and crossing block management
- IITA Seed Processing and Inventory Management
- IITA Trial Management
- IITA Weed Control and Management
- IITA Phenotyping Data Management
- IITA Harvesting and Harvest Evaluation
- IITA DNA extraction
- IITA Leaf Sampling
- IITA High Throughput Phenotyping using NIRS
- Maps
- Cassava 2011
- Cassava 2013 GBS Map
- Cassava 2014 GBS Map
- Genome
- Cassava Genome Browser at JGI (version 6.1)
- About
- About NextGen Cassava
- Contact
- Cite CassavaBase
- Manual
- Video Tutorials
- FAQ
- Forum
- FTP site
- Project documents
- DB Stats
- Recent Activity
-
Advanced Login
This site uses cookies to provide logins and other features. Please accept the use of cookies by clicking Accept.
Cassava Genomes
Sequencing wild and cultivated cassava reveals hybridization and genetic diversity
- Browse the cassava genomev6.1 @ JGI
- BLAST search @ JGI
- Download the annotations @ JGI
- Download the Genome Sequence v6.1 @ JGI
- Design VIGS constructs
Breeding programs
Search, retrieve, save breeding trials
- Search accessions and trials
- Make crossings
- Fieldbook App & uploading
- Cassava Trait Ontology
SolGS
Genomic selection and molecular breeding
- Genomic Selection
- Population Structure
- Maps & Marker Search
NextGenCassava Community
& Partners
- GCP21
- RTB program
- GatesNotes on Cassava
- Mueller lab @BTI
SGN SlideShare
Slides from conferences and courses
-
Cassavabase @ PAG Meeting 2016 SolGS @ PAG Meeting 2016 Cassavabase Workshop @ WCRTC Meeting 2015 Wizard search and list manager video demo
- Genomics
- Breeding
- Genomic selection
- Community
- Slideshare
New to the database?
Click this button to begin our guided help.
What are you interested in? For General Help
Upload an experimental field trial into the database that you have saved on your computer in Excel
Design a completely new experimental field trial in the database
Catalog your available seed inventory into the database
Upload phenotypic data into the database that you have saved on your computer in Excel
Plan tissue sampling
Upload crosses and crossing information into the database
Print barcode labels for my experiment (for your plots or plants or tissue samples in the field, or for your 96 well plate and tissue samples)
Analyze phenotypic performance across trials
Prepare a 96 or 384 well plate for a genotyping experiment
Upload VCF genotypic data
Tissue Sampling
-
Intro
-
Sampling Level
-
Select a field trial
-
Plant Entries
-
Create Tissue Sample Entries
-
This workflow will guide you through tissue sampling an experiment
Tissue samples collected from the field are linked to a single plant, which is in turn linked to a single plot.
Many tissue samples can be created for each plant.
Each tissue sample has a globally unique name.
A unique tissue sample is present in each well of a genotyping plate (96 or 384 well plates).
The tissue sample in a 96 well plate can originate from another tissue sample name, plant name, plot name, or accession name.
Go to Next Step -
Accession Level: The sample is not from a field trial entity and only the accession name is known.
At which level do you plan to keep track of your sampling?
Plot Level: Each plot in the field has a unique identifier, ideally with a barcode label.
Plant Level: Each plant in the field has a unique identifier, ideally with a barcode label.
Tissue Sample Level: Each tissue sample collected from the field has a unique identifier, ideally with a barcode label.
Go to Next Step -
Select a field trial
Field trial is not relevant for the type of tissue sampling you selected. Go to next step.
Go to Next StepSelect Trial name Description Breeding program Folder Year Location Trial type Design Planting Date Harvest Date Download
Go to Next Step -
Plant entries in your field trial
Plant entries not relevant for the type of tissue sampling you selected. Go to next step.
Go to Next StepPlant entries exist for this trial. Go to next step.
Go to Next StepPlease create plant entries for this trial.
Number of plants per plot:Inherits Treatment(s) From Plots:
Submit -
Create tissue sample entries for this trial
Field trial tissue sample entries not relevant for the type of tissue sampling you selected. Go to next step.
Go to Next StepTissue sample entries exist for this trial. Go to next step.
Go to Next StepNumber of tissue samples per plant:Inherits Treatment(s) From Plots:
Submit
Complete! You have all the entities you need to conduct your sampling.
- All of the entities that you want to sample are saved in the database and available to use!
- You can print barcodes for the entities you intend to sample on. These barcodes can be attached to your collection vials/containers to assist during sampling.
- After you have finished sampling, you can use these entities as source material for a genotyping plate (96 or 384 well plate). Click the button below to create a genotyping plate now, if you will create a 96 or 384 well plate.
- The Android Coordinate application can help you create 96 or 384 well plates. Alternatively you can create your plate layout in Excel and upload it.
Complete! You have all the entities you need to conduct your sampling.
- All of the entities that you want to sample are saved in the database and available to use!
- You can print barcodes for the entities you intend to sample on. These barcodes can be attached to your collection vials/containers to assist during sampling.
- After you have finished sampling, you can use these entities as source material for a genotyping plate (96 or 384 well plate). Click the button below to create a genotyping plate now, if you will create a 96 or 384 well plate.
- The Android Coordinate application can help you create 96 or 384 well plates. Alternatively you can create your plate layout in Excel and upload it.
Workflow for seedlot inventory
I have new seedlots that need to be added into the database.
I conducted an inventory (in weight(g)) and want to update the database to reflect the current state of the inventory.
Workflow for uploading phenotypes
Please refer to the Documentation
Workflow for trial barcoding
Please refer to the Documentation
Workflow for comparing one or many trials
Please refer to the Documentation
Upload Existing Trial(s)
-
Intro
-
File Formatting
-
Enter trial information
-
Trial Linkage
-
Fix missing accessions problem
-
Fix missing seedlots problem
-
Try submitting trial again
-
This workflow will guide you through uploading a new trial or trials into the database
A field trial represents plots in the field where each plot has a globally unique plot_name, a sequential plot_number that is unique in the trial (e.g. 101, 102, 103 for three separate plots), and an accession_name representing the genotype being tested in that plot. In cases where a cross/family is being evaluated (e.g. F1 hybrid, backcrossing), a cross_unique_id or a family_name can be used instead of an accession_name. Each plot can belong to different blocks (block_number) and reps (rep_number) depending on the experimental design you are using (e.g. complete block vs augmented design). Each plot can have a row_number and col_number indicating the relative position of the plot in the field.
If a specific accession is a check or control, you can indicate the plots that that accession is planted in as controls using is_a_control.
You can provide the specific seedlot_name planted in each plot, along with the number of seeds (num_seed_per_plot) and/or the weight (g) of seed (weight_gram_seed_per_plot) that were used.
A trial can represent a yield trial, a phenotyping trial, a crossing block, a greenhouse, a nursery, etc.
A plot can have many plants, which the database can track as separate entities, allowing you to record plant level observations and information.
Go to Next Step -
- Single Trial Design
- Multiple Trial Designs
Go to Next StepFile format information
Single trial spreadsheet
Single Trial Designs may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
File format information
Multiple trial spreadsheet
Ignore Warnings:Email Alert:Email:
Upload Trial Designs Reload Page
Multiple Trial Designs may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
-
Enter information about the experiment and upload your trial layout
Trial Name:Breeding Program:5CPBTICARICHCIATCIP-genebankCNRACornellCSIR-CRIEmbrapaIDIAFIITAINERA_IITA_DRCISABUITCKALROKUNaCRRINRCRIRayongSLARITARIUACUHUNILA-IndonesiaZARILocation:RestrepoIgbariamGranadaFlorenciabwangaMvuaziNaliendeleKokrokoChokweCalabarJaguaripe (BA) - Fazenda Esperan�aCorozal. Sucre, ColombiaAgborSuakokoKibahaIshiaguBarahonaNjalaSotoubouaBuenos AiresAlbaniaItanhem (BA)IlorinAcacias. Meta, ColombiaVerdelandia (MG)-Brasnica Fazenda OrienteCIATDarien. Valle, ColombiaEl Espinal. Tolima, ColombiaTerra Alta (PA)[Computation]Puerto Caicedo. Putumayo, ColombiaFlorestal (MG) - UFV Campus FlorestalLUWEEROMatazulAkwa IbomLaje (BA)-RoqueEjuraVilla Garzon. Putumayo, ColombiaLuruacoHomboloQuilcace. Cauca, ColombiaTumacoCaribiaOvejasMomilLomeMukonoSabanagrandeBlamaSao Mateus (ES)KiggumbaNjuliMakokaZariaIITA-DARArmeroZomboAnlong Veng District, Oddar Meanchey provinceMutata. Antioquia, ColombiaAguazulValencia. Cordoba, ColombiaQuang NgaiAgustin CodazziMakeniKabalaNametilPalmiraBolivarKwaraKazilamuyagaTamalameque. Cesar, ColombiaBaranoa. Atlantico, ColombiaEsplanada (BA) - CachoeiraUkereweNhacoongoIbadanLaje (BA)-GaviaoKaomaMangabeira (BA)-IF BaianoGairoBuginyanyaMarukuMtwapa2an co chauthanh, tayninhVarzedo (BA)UmbeluziSao Francisco de Itabapoana (RJ)-Industria Dona ChicaBukembaCampos Novos Paulista (SP)-Tereos SyralCIAT. Valle, ColombiaOgoniInharrimeBulingaUyoEmbuBarrancabermejaKabangweDarienCereteFumesuaSiayaMacapa (AP)SabanalargaEl Overo. Valle, ColombiaLa Colina. Sucre, ColombiaCaldonoPallisaSabanalarga. Atlantico, ColombiaKhao Hinsorn Research Center, Kasetsart University, Chachoengsao provinceRatanak Mondul district, Battambang provinceMasakaEl Olivo. Cordoba, ColombiaApiayVitoria da Conquista (BA) - Fecularia ConquistaKaberamaidoSulutiSan Vicente. Santander, ColombiaMontenegro. Quindio, ColombiaTouros (RN)-PrataBusiaAremasain. Guajira, ColombiaunspecifiedMutataChiengiSanta CruzAbujaUniversity of HawaiiAkureOhawuCarepaTay NinhLirakasuluApiay. Meta, ColombiaBugaPetrolina (PE)-UNIVASFPatiaMichikichiniItasyAgo-OwuMkondeziPopayanDoncello. Caqueta, ColombiaDivoPajau. Brasil, BrazilQuilcaceFlorencia. Caqueta, ColombiaTangakonaMontenegroBundaPuerto GaitanBarranquilla. Atlantico, ColombiaCorozalPinheiros (ES)MontanitaChitedzeJeddoLao NgamSikhiu is a district (amphoe) in the western part of Nakhon Ratchasima provinceCienaga. Magdalena, ColombiaTol�Marechal Candido Rondon (PR)-ATIMOPEl EspinalHoma BayArmeniaTESTSanto Tomas. Atlantico, ColombiaMkurangaKisesaAssin FosuYopal. Casanare, ColombiabadagryObuduNaphokLa Dolores. Valle, ColombiaSenjehRufunsaUkiriguruSampues. Sucre, ColombiaCajibioCora��o de Maria (BA)GongoniLa HormigaRakaiPalmasecaLoricaCruz das Almas (BA)-UFRB-CandealMargibiAKUMADANTracuateua (PA)Tol�viejoPopayan. Cauca, ColombiaAcaciasTauramenaKipopoAgbarhoNgandajikaSan Miguel. Sucre, ColombiaOrito. Putumayo, ColombiaPuerto Asis. Putumayo, ColombiaCumaral. Meta, ColombiaRubiriziBuikweKalomoSan Martin. Meta, ColombiaCerete. Cordoba, ColombiaMityanaOsunKiyakaPivijaySinceMontanita. Sucre, ColombiaConde (BA)-CanguritoNyankpalaVitoria da Conquista (BA)Prado (BA)MbuniHung YenLaje (BA) - Fazenda Sombra VerdeDeltaBoyce Thompson InstitutePitalitoKasinthukaPuerto AsisWenchiSan VicenteCaracoli. Atlantico, ColombiaKebbiAlupeCapanema (PA)RubonaChatoCalotoUsiacuriibadanSanta Cruz. Atlantico, ColombiaLa Hormiga. Putumayo, ColombiaMonteriaLaje (BA)-Rio de Areia 1Rio Frio. Magdalena, ColombiaEl Carmen. Bolivar, ColombiaTeresina (PI)OrtegaIresiYopalFonsecaCaracoliEl Salado. Cordoba, ColombiaPuerto LopezLagoa D'Anta (RN)ManLagoa D'anta (RN)-LopesOnneKWALEPuerto Gaitan. Meta, ColombiaConceicao dos Ouros (MG)UmudikePojuca (BA)RiversMedia Luna. Magdalena, ColombiaFadaInaBambiLukwakwaMalambo. Atlantico, ColombiaCornell BiotechChilimbaLoroRio FrioDoncelloPalmar de VarelaMogovolasSan Antonio de PalmitoSon LaMtwapaWarriNachingweaBulegeniVerdelandia (MG)-Brasnica Fazenda VilyamaZanzibarTapioca Development Institute (TDI), located in Huay Bong, Dan Khun Thot District, Nakhon RatchasimaPhu YenJamundi. Valle, ColombiaMalamboIkennePureza (RN)Puerto Lopez. Meta, ColombiaFarakobaHanoiNgomaKasuluSevillaItamaraju (BA)Ban Khao Luk Chang, Ta Phraya Sistrict, Sa Kaeo provinceCienagaS. de Quilichao. Cauca, ColombiaEl MiraEdoGuanambi (BA)-IF BaianoPolonuevoCruz Das Almas (BA) - UFRB CAMABSerra dos Aimores (MG)-Cachoeira da MataMahondaCarimagua. Meta, ColombiaLlanosVilla GarzonArmenia. Quindio, ColombiaMarataizes (ES)LiupoMonteria (UNICORDOBA). Cordoba, ColombiaLaje (BA)-Rio de Areia 1MigoriWakisoCruz das Almas (BA)-UFRB-PP1GbarpoluEketPuerto CaicedoBarranca De Upia. Casanare, ColombiaMansaLa Libertad. Meta, ColombiaLaberinto. Sucre, ColombiaCrossRiverMondomoPokuase-AccraLondrina (PR-Afapo)Teixeira de Freitas (BA)Mimoso do Sul (ES)Fumesua-KumasiCarimaguaBayelsaValledupar. Cesar, ColombiaPonta Pora (MS)-Assentamento ItamaratiMogincualBuenaventuraBouakeItiuba (BA)San PabloKisesa-MaguEl SaladoDewoinMomil. Cordoba, ColombiaBanteay Meanchey province Banteay MeancheyMulunguMsambweniNgabuCandelaria. Valle, ColombiaAlagoinhas (BA)-Boa UniaoNecocliKanoCaloto. Cauca, ColombiaCabuyaro. Meta, ColombiaSan MartinSoeng Sang is a district in the southeastern part of Nakhon Ratchasima provinceInhambupe (BA)-BotelhoThateng district, Sekong provinceBuga. Valle, ColombiaCantaclaroS. de QuilichaoCorozal. Sucre, ColombiaNational Corn and Sorghum Research Center (Suwan Farm), Kasetsart University Nakhon Ratchasima provinceLuruaco. Atlantico, ColombiaRepelon. Atlantico, ColombiaLa Libertad. Meta, ColombiaIlesaPend. , ColombiaVijes. Valle, ColombiaNaCRRI, Central UgandaLa UnionRokuprUnknownunknown2MbararaOtobiAugusto Correa (PA)MuhangaAzuaRwebitabaUbiajadavieNiaouliJamundiChamkar Leu districtBarranquillaAtivemeNgettaGranada. Meta, ColombiaCampecheJosIBARAPAEl Carmen de BolivarFrancisco PizarroSatiro Dias (BA)-Assentamento PapagaioPalmaseca. Valle, ColombiaLaje (BA)-Novo Horizonte 2ASan PedroCienaga De Oro. Cordoba, ColombiaMalam MadoriKumasiKamaConde (BA)-HumaitaSerereNecocli. Antioquia, ColombiaCorpoica PalmiraBetuliaLaje (BA)-Rio de Areia 2MocubaNigerDanyiTororoKizimbaniFonseca. Guajira, ColombiaOshogboPitalito. Atlantico, ColombiaLaberintoChambeziAdetaSantaguedaKakamegaTchadNsukkaCabuyaroKubwaIRRUALa LibertadLaje (BA)-Fazenda Sao JorgekaseseBaranoaPalmar de Varela. Atlantico, ColombiaMatazul. Meta, ColombiaBwangaKisumuPescador. Cauca, ColombiaLaje (BA)-RogerioSahagun. Cordoba, ColombiaChitalaAbidjanSabanalarga. Atlantico, ColombiaNgettaMokwaCarranzo. Cordoba, ColombiaMoralesSampuesChinuPouso Alegre (MG)Cajibio. Cauca, ColombiaLaje (BA)-Novo Horizonte 1Dong NaiYangambiNebbiPokuaseDaklakMorales. Cauca, ColombiaNyagatareMontanha (ES) - Fecularia ConquistaKibaaleBarranca De UpiaEl OveroArmero. Tolima, ColombiaCarepa. Antioquia, ColombiaSahagunLa Union. Sucre, ColombiaAlcobaca (BA)KilibaBetulia. Sucre, ColombiaAlbania. Sucre, ColombiaKaseseCIAT. Valle, ColombiaPendembuMsabahaBarrancabermeja. Santander, ColombiaChinu. Cordoba, ColombiaOritolossaVijesBela Vista de Goias (GO)Laje (BA)-Novo Horizonte 2BBolikham district, Bolikhamxay provinceCruz Das Almas (BA)-CNPMF-Area 2Namulonge-SendusuDamongoPatia. Cauca, ColombiaRestrepo. Meta, ColombiaNeivaCostaRepelonSanto TomasEntre Rios (BA)MIKOCHENICaribia. Magdalena, ColombiaChochoLaje (BA) - CapelaQuissama (RJ)-PMQ HortoKadunaweBom Jesus da Lapa (BA) - IF BaianoEkitiPitalito. Atlantico, ColombiaOgutaNong Yai is a district in the province ChonburiCandelariaMolineros. Atlantico, ColombiaPescadorNamulongeWenchi-BALa CumbreLaje (BA) - RailtonSanta Isabel do Para (PA)Santo Tomas. Atlantico, ColombiaMedia LunaMorogoroEl OlivoTauramena. Casanare, ColombiaCumaralValleduparFloridaMondomo. Cauca, ColombiaMotiloniaAguazul. Casanare, ColombiaLaje (BA)-Novo RumoCienaga De OroStung Treng Province, Stung TrengEuclides da Cunha (BA)Cruz Das Almas (BA) - UFRB - EstabuloAremasainLaje (BA)-Novo Horizonte 1Asuoiday, tanchau, tayninhKibosKamuliLa DoloresAlagoinhas (BA)COLDStore, RACK1, Shelf2, Cruz Das Almas (BA) CNPMF - CitrusRuziziPlainIkot AfangaBengouPivijay. Magdalena, ColombiaKogiAruaAgenbodeValenciaNatagaimaCampos dos Goytacazes (RJ)-UENFILONGABundibugyoEgbemaKakonkoMubendeSanto Amaro (BA)BarrancasCachoeira de Minas (MG)Dourados (MS)-UFGDDOKOLOCruz Das Almas (BA) - CNPMF - Area 1 (Ladeira maracuja)Los PalmitosGinebraTrial Type:Year:Planting Date (MM-DD-YYYY):Transplanting Date(MM-DD-YYYY):Plot Width (m):Plot Length (m):Field Size (ha):Plants per Plot:Inherits Treatment(s) From Plots:Creates plant entries for each plot. Ignore if not adding plant entries.
Assign row and column data to plants within plots?One plant per (row,column) coordinate. Rows and columns will be populated in a zigzag pattern. Row and column numbers start at 1 within each plot.
Number of rows per plot Number of columns per plot Description:Stock Type Being Evaluated in Trial:Select a stock type accession cross family_nameDesign Type:Completely Randomized Complete Block Resolvable Row-Column Doubly-Resolvable Row-Column Un-Replicated Diagonal Design Augmented Row-Column Alpha Lattice Lattice Augmented Modified Augmented Design Nursery/Greenhouse Split Plot Strip Plot Partially Replicated WestcottUpload File:
Go To Next Step -
Is your trial linked with other field trials, genotyping plates, or crossing experiments in the database? If you are unsure, you can skip this. This information can be added from the trial detail page after the trial is saved.
Is this trial following-up a previous field trial?:No YesSelect the trial(s) which preceded this trial:If you go on to collect tissue samples for creating a 96 well plate for genotyping, when adding the genotyping plate (96 well plate layout) to the database you can use plot names or plant names or tissue sample names from this field trial. By doing so, we can create linkage between this field trial and the genotyping plate.
Will this trial be genotyped?:No YesIf you go on to perform crosses on this field trial, each cross can be linked to specific female and male plots. When you upload these crosses we can then automatically link this field trial to the crossing experiment in the database.
Will crosses be done on this trial?:No Yes
Check this box to ignore any possible warning messages and save the trial to the database.
Ignore Warnings?:
First validate the form Upload Trial -
Fixing the missing accession(s) problem
- Accessions tested in your trial must exist in the database prior to adding your trial. The reason for this is that an accession can be tested in many trials and therefore exists as a separate entity in the database. We also want to be careful about adding new accessions into the database because we do not want incorrectly duplicated data.
- When adding accessions into the database, you can use either a list of accessions or an Excel file.
Add your accessions to the database
Once all your accessions are in the database Click Here
Trial Upload Error Messages
-
Fixing the missing seedlot(s) problem
- Seedlots tested in your experimental trial must exist in the database prior to adding your trial. The reason for this is that a seedlot can be tested in many trials and therefore exists as a separate entity in the database. We also want to be careful about adding new seedlots into the database because we do not want data to be incorrectly linked to duplicates.
- When adding seedlots into the database, you can upload an Excel file or you can add seedlots one at a time.
- Upload Excel file
- Add One Seedlot
- Upload Excel file
Once all your seedlots are in the database Click Here
Trial Upload Error Messages
-
Submit your trial again. You should have corrected all errors by now, but if not please take a look at the errors in the red box below. You can continue to modify your file and then click Upload until it works.
Upload Trial
There exist these problems in your file:
Finished! Your trial is now in the database
The trial file was uploaded successfully
- You may want to proceed to the trial detail page for the trial you just created.
- You can print barcodes for the plots or plants or tissue samples in this trial.
- You an add phenotypes for the plots or plants in this trial now.
Finished! Your trial is now in the database
The trial file was uploaded successfully
- You may want to proceed to the trial detail page for the trial you just created.
- You can print barcodes for the plots or plants or tissue samples in this trial.
- You an add phenotypes for the plots or plants in this trial now.
Upload Template Information
| Stock type being evaluated in this trial: accession Stock type being evaluated in this trial: accession |
The first row (header) must contain the following:
| plot_name | accession_name | plot_number | block_number | is_a_control | rep_number | range_number | row_number | col_number | seedlot_name | num_seed_per_plot | weight_gram_seed_per_plot | entry_number |
plot_name,accession_name,plot_number,block_number,is_a_control,rep_number,range_number,row_number,col_number,seedlot_name,num_seed_per_plot,weight_gram_seed_per_plot,entry_number
| Stock type being evaluated in this trial: cross unique id Stock type being evaluated in this trial: cross unique id |
The first row (header) must contain the following:
| plot_name | cross_unique_id | plot_number | block_number | is_a_control | rep_number | range_number | row_number | col_number | seedlot_name | num_seed_per_plot | weight_gram_seed_per_plot | entry_number |
plot_name,cross_unique_id,plot_number,block_number,is_a_control,rep_number,range_number,row_number,col_number,seedlot_name,num_seed_per_plot,weight_gram_seed_per_plot,entry_number
| Stock type being evaluated in this trial: family name Stock type being evaluated in this trial: family name |
The first row (header) must contain the following:
| plot_name | family_name | plot_number | block_number | is_a_control | rep_number | range_number | row_number | col_number | seedlot_name | num_seed_per_plot | weight_gram_seed_per_plot | entry_number |
plot_name,family_name,plot_number,block_number,is_a_control,rep_number,range_number,row_number,col_number,seedlot_name,num_seed_per_plot,weight_gram_seed_per_plot,entry_number
- accession_name or cross_unique_id or family_name (must exist in the database. This is the accession or cross unique id or family name being tested in the plot.)
- plot_number (a sequential number for the plot in the field (e.g. 1001, 1002, 2001, 2002). These numbers should be unique for the trial.)
- block_number (a design parameter indicating which block the plot is in)
- plot_name (must be unique across entire database. If not provided in the file, it will be automatically generated as {trial_name}-PLOT_{plot_number}.)
- is_a_control (type 1 in this field if the plot is a control, otherwise leave blank. generally you will have accessions/cross unique ids/family names that are controls, so you should indicate the plots of those accessions/cross unique ids/family names as a control.)
- rep_number (replicate number, numeric)
- range_number (range number. often synonymous with col_number, numeric)
- row_number (row number. If the field is a grid, this represents the y coordinate, numeric, required for field map generation.)
- col_number (column number. If the field is a grid, this represents the x coordinate. Sometimes called range_number, numeric, required for field map generation.)
- seedlot_name (the seedlot from where the planted seed originated. Must exist in the database)
- num_seed_per_plot (number seeds per plot. Seed is transferred from seedlot mentioned in seedlot_name. Numeric)
- weight_gram_seed_per_plot (weight in gram of seeds in plot. seed is transferred from seedlot mentioned in seedlot name. Numeric)
- entry_number (a trial-level entry number assigned to the stock. Numeric)
- intercrop_accession_name (the name(s) of additional accessions that are planted in this plot along with the primary accession. the name(s) must already exist in the database. if you have more than one intercropped accession, you can include each name separated by a comma in one column or include additional columns with this header.)
- Experimental treatments are handled in much the same way as phenotypes, and can be uploaded from the trial detail page after trial creation. They may also be included as additional columns in a trial upload, formatted as experimental treatment|EXPERIMENT_TREATMENT:0000001
Only the required fields are necessary to include in the upload template. You may add any additional optional fields. The fields can be in any order.
Upload Template Information
Multiple Trial Designs:
Header:
The first row (header) must contain the following, which is an expansion of the single trial design header:
| trial_name | breeding_program | location | year | transplanting_date | design_type | description | trial_type | trial_stock_type | plot_width | plot_length | field_size | planting_date | harvest_date | plot_name | accession_name | plot_number | block_number | is_a_control | rep_number | range_number | row_number | col_number | seedlot_name | num_seed_per_plot | weight_gram_seed_per_plot | entry_number |
trial_name,breeding_program,location,year,transplanting_date,design_type,description,trial_type,trial_stock_type,plot_width,plot_length,field_size,planting_date,harvest_date,plot_name,accession_name,plot_number,block_number,is_a_control,rep_number,range_number,row_number,col_number,seedlot_name,num_seed_per_plot,weight_gram_seed_per_plot,entry_number
Required fields:- trial_name (Must be unique across entire database. It is often a concatenation of the year, transplanting_date, purpose, unique number, and location.)
- breeding_program (The name of breeding program that managed the trial, must exist in the database.)
- location (The name or abbreviation of the location where the trial was held, must exist in the database.)
- year (The year the trial was held.)
- design_type (The shorthand for the design type, must exist in the database. Possible values include CRD (Completely Randomized Design), RCBD (Randomized Complete Block Design), RRC (Resolvable Row-Column), DRRC (Doubly-Resolvable Row-Column), URDD (Un-Replicated Diagonal Design), ARC (Augmented Row-Column), Alpha (Alpha Lattice Design), Lattice (Lattice Design), Augmented (Augmented Design), MAD (Modified Augmented Design), greenhouse (undesigned Nursery/Greenhouse), splitplot (Split Plot), stripplot (Strip Plot / Split Block), p-rep (Partially Replicated), Westcott (Westcott Design))
- description (Additional text with any other relevant information about the trial.)
- accession_name OR cross_unique_id OR family_name (The accession, cross, or family being tested in the plot, must exist in the database.)
- plot_number (A sequential number for the plot in the field (e.g. 1001, 1002, 2001, 2002). These numbers should be unique for the trial.)
- block_number (A design parameter indicating which block the plot is in.)
- plot_name (Must be unique across entire database. If not provided in the file, it will be automatically generated as {trial_name}-PLOT_{plot_number})
- trial_type (The name of the trial type, must exist in the database. Possible values include Seedling Nursery, phenotyping_trial, Advanced Yield Trial, Preliminary Yield Trial, Uniform Yield Trial, Variety Release Trial, Clonal Evaluation, genetic_gain_trial, storage_trial, heterosis_trial, health_status_trial, grafting_trial, Screen House, Seed Multiplication, crossing_block_trial, Specialty Trial)
- trial_stock_type (The type of stocks that are being evaluated in the trial. Can be either 'accession', 'cross', or 'family_name'. When not provided, 'accession' is used as the default)
- plot_width (plot width in meters)
- plot_length (plot length in meters)
- field_size (field size in hectares)
- planting_date (Date of Planting in YYYY-MM-DD format)
- transplanting_date(The transplanting_date of the trial was conducted. Date in YYYY-MM-DD format)
- harvest_date (Date of Harvest in YYYY-MM-DD format)
- is_a_control (type 1 in this field if the plot is a control, otherwise 0 or leave blank. generally you will have accessions that are controls, so you should indicate the plots that that accession is in as a control.)
- rep_number (replicate number, must be numeric)
- range_number (range number. often synonymous with col_number, must be numeric)
- row_number (row number. if the field is a grid, this represents the y coordinate, numeric, required for field map generation.)
- col_number (column number. if the field is a grid, this represents the x coordinate. sometimes called range_number, numeric, required for field map generation.)
- seedlot_name (the seedlot from where the planted seed originated. must exist in the database)
- num_seed_per_plot (number seeds per plot. seed is transferred from seedlot mentioned in seedlot_name. numeric)
- weight_gram_seed_per_plot (weight in gram of seeds in plot. seed is transferred from seedlot mentioned in seedlot name. numeric)
- entry_number (a trial-level entry number assigned to the stock. Numeric)
- intercrop_accession_name (the name(s) of additional accessions that are planted in this plot along with the primary accession. the name(s) must already exist in the database. if you have more than one intercropped accession, you can include each name separated by a comma in one column or include additional columns with this header.)
- Experimental treatments are handled in much the same way as phenotypes, and can be uploaded from the trial detail page after trial creation. They may also be included as additional columns in a trial upload, formatted as experimental treatment|EXPERIMENT_TREATMENT:0000001
Trials may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Upload Trial Metadata
This upload can be used to update the metadata of trials that have already been added to the database
Any metadata provided in the upload file will replace any existing metadata. Blank values in the upload file will leave the existing metadata unchanged.
| File format information |
Trial Metadata may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Upload Trial Metadata Template Information
The first row (header) should contain the following:
| trial_name | breeding_program | folder | location | year | transplanting_date | planting_date | harvest_date | design_type | description | trial_type | plot_width | plot_length | field_size |
- trial_name: the name of the trial (must already exist in the database)
Optional values:
- new_trial_name (A new name for the trial, must not already exist in the database)
- breeding_program (The name of breeding program that managed the trial, must exist in the database.)
- folder (The name of the folder to display the trial in on the Manage > Field Trials page. If the folder does not exist, a new one will be created under the trial's breeding program)
- location (The name or abbreviation of the location where the trial was held, must exist in the database.)
- year (The year the trial was held.)
- transplanting_date (The transplanting_date of the trial was conducted. Date in YYYY-MM-DD format or 'remove' to remove the date)
- planting_date (Date of Planting in YYYY-MM-DD format or 'remove' to remove the date)
- harvest_date (Date of Harvest in YYYY-MM-DD format or 'remove' to remove the date)
- design_type (The shorthand for the design type, must exist in the database. Possible values include CRD (Completely Randomized Design), RCBD (Randomized Complete Block Design), RRC (Resolvable Row-Column), DRRC (Doubly-Resolvable Row-Column), URDD (Un-Replicated Diagonal Design), ARC (Augmented Row-Column), Alpha (Alpha Lattice Design), Lattice (Lattice Design), Augmented (Augmented Design), MAD (Modified Augmented Design), greenhouse (undesigned Nursery/Greenhouse), splitplot (Split Plot), p-rep (Partially Replicated), Westcott (Westcott Design))
- description (Additional text with any other relevant information about the trial.)
- trial_type (The name of the trial type, must exist in the database. Possible values include Seedling Nursery, phenotyping_trial, Advanced Yield Trial, Preliminary Yield Trial, Uniform Yield Trial, Variety Release Trial, Clonal Evaluation, genetic_gain_trial, storage_trial, heterosis_trial, health_status_trial, grafting_trial, Screen House, Seed Multiplication, crossing_block_trial, Specialty Trial)
- plot_width (plot width in meters)
- plot_length (plot length in meters)
- field_size (field size in hectares)
Trial Metadata may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Design New Trial
-
Intro
-
Trial Information
-
Design Information
-
Trial Linkage
-
Field Map Information
-
Custom Plot Naming
-
Review Designed Trial
-
This workflow will guide you through designing a new trial in the database
A field trial represents a field where each plot has a globally unique plot name, a sequential plot number that is unique in the trial (e.g. 101, 102, 103 for three separate plots), and an accession representing the genotype being tested in that plot. In cases where crosses/families are being evaluated (e.g. F1 hybrid, backcrossing), cross unique ids or family names can be used instead of accessions. Each plot can belong to different blocks and reps depending on the experimental design you are using (e.g. complete block vs augmented design). Each plot can have a row number and col number indicating the relative position of the plot in the field.
To design a trial you need to provide a globally unique trial name. The plot names will be generated based on the trial name you provide (e.g. if the trial name is 2018MyTrial, plot_names will be generated like 2018MyTrial_101, 2018MyTrial_102, etc).
You also need to provide a list of accessions, cross unique ids or family names to use. Based on the design you have picked, the accessions, cross unique ids or family names will be randomized over the blocks or replicates in the trial.
You can provide a list of accessions to use as controls or checks in your experiment.
Depending on the design you have picked, you will need to provide different design parameters (e.g. for complete block you will need to provide number of blocks, while for alpha lattice you will need to provide block size and number of replicates.).
A trial can represent a yield trial, a phenotyping trial, a crossing block, a greenhouse, a nursery, etc.
A plot can have many plants, which the database can track as separate entities, allowing you to record plant level observations and information.
Go to Next Step -
Enter basic information about the trial
Breeding Program:5CPBTICARICHCIATCIP-genebankCNRACornellCSIR-CRIEmbrapaIDIAFIITAINERA_IITA_DRCISABUITCKALROKUNaCRRINRCRIRayongSLARITARIUACUHUNILA-IndonesiaZARILocations: (One or More)RestrepoIgbariamGranadaFlorenciabwangaMvuaziNaliendeleKokrokoChokweCalabarJaguaripe (BA) - Fazenda Esperan�aCorozal. Sucre, ColombiaAgborSuakokoKibahaIshiaguBarahonaNjalaSotoubouaBuenos AiresAlbaniaItanhem (BA)IlorinAcacias. Meta, ColombiaVerdelandia (MG)-Brasnica Fazenda OrienteCIATDarien. Valle, ColombiaEl Espinal. Tolima, ColombiaTerra Alta (PA)[Computation]Puerto Caicedo. Putumayo, ColombiaFlorestal (MG) - UFV Campus FlorestalLUWEEROMatazulAkwa IbomLaje (BA)-RoqueEjuraVilla Garzon. Putumayo, ColombiaLuruacoHomboloQuilcace. Cauca, ColombiaTumacoCaribiaOvejasMomilLomeMukonoSabanagrandeBlamaSao Mateus (ES)KiggumbaNjuliMakokaZariaIITA-DARArmeroZomboAnlong Veng District, Oddar Meanchey provinceMutata. Antioquia, ColombiaAguazulValencia. Cordoba, ColombiaQuang NgaiAgustin CodazziMakeniKabalaNametilPalmiraBolivarKwaraKazilamuyagaTamalameque. Cesar, ColombiaBaranoa. Atlantico, ColombiaEsplanada (BA) - CachoeiraUkereweNhacoongoIbadanLaje (BA)-GaviaoKaomaMangabeira (BA)-IF BaianoGairoBuginyanyaMarukuMtwapa2an co chauthanh, tayninhVarzedo (BA)UmbeluziSao Francisco de Itabapoana (RJ)-Industria Dona ChicaBukembaCampos Novos Paulista (SP)-Tereos SyralCIAT. Valle, ColombiaOgoniInharrimeBulingaUyoEmbuBarrancabermejaKabangweDarienCereteFumesuaSiayaMacapa (AP)SabanalargaEl Overo. Valle, ColombiaLa Colina. Sucre, ColombiaCaldonoPallisaSabanalarga. Atlantico, ColombiaKhao Hinsorn Research Center, Kasetsart University, Chachoengsao provinceRatanak Mondul district, Battambang provinceMasakaEl Olivo. Cordoba, ColombiaApiayVitoria da Conquista (BA) - Fecularia ConquistaKaberamaidoSulutiSan Vicente. Santander, ColombiaMontenegro. Quindio, ColombiaTouros (RN)-PrataBusiaAremasain. Guajira, ColombiaunspecifiedMutataChiengiSanta CruzAbujaUniversity of HawaiiAkureOhawuCarepaTay NinhLirakasuluApiay. Meta, ColombiaBugaPetrolina (PE)-UNIVASFPatiaMichikichiniItasyAgo-OwuMkondeziPopayanDoncello. Caqueta, ColombiaDivoPajau. Brasil, BrazilQuilcaceFlorencia. Caqueta, ColombiaTangakonaMontenegroBundaPuerto GaitanBarranquilla. Atlantico, ColombiaCorozalPinheiros (ES)MontanitaChitedzeJeddoLao NgamSikhiu is a district (amphoe) in the western part of Nakhon Ratchasima provinceCienaga. Magdalena, ColombiaTol�Marechal Candido Rondon (PR)-ATIMOPEl EspinalHoma BayArmeniaTESTSanto Tomas. Atlantico, ColombiaMkurangaKisesaAssin FosuYopal. Casanare, ColombiabadagryObuduNaphokLa Dolores. Valle, ColombiaSenjehRufunsaUkiriguruSampues. Sucre, ColombiaCajibioCora��o de Maria (BA)GongoniLa HormigaRakaiPalmasecaLoricaCruz das Almas (BA)-UFRB-CandealMargibiAKUMADANTracuateua (PA)Tol�viejoPopayan. Cauca, ColombiaAcaciasTauramenaKipopoAgbarhoNgandajikaSan Miguel. Sucre, ColombiaOrito. Putumayo, ColombiaPuerto Asis. Putumayo, ColombiaCumaral. Meta, ColombiaRubiriziBuikweKalomoSan Martin. Meta, ColombiaCerete. Cordoba, ColombiaMityanaOsunKiyakaPivijaySinceMontanita. Sucre, ColombiaConde (BA)-CanguritoNyankpalaVitoria da Conquista (BA)Prado (BA)MbuniHung YenLaje (BA) - Fazenda Sombra VerdeDeltaBoyce Thompson InstitutePitalitoKasinthukaPuerto AsisWenchiSan VicenteCaracoli. Atlantico, ColombiaKebbiAlupeCapanema (PA)RubonaChatoCalotoUsiacuriibadanSanta Cruz. Atlantico, ColombiaLa Hormiga. Putumayo, ColombiaMonteriaLaje (BA)-Rio de Areia 1Rio Frio. Magdalena, ColombiaEl Carmen. Bolivar, ColombiaTeresina (PI)OrtegaIresiYopalFonsecaCaracoliEl Salado. Cordoba, ColombiaPuerto LopezLagoa D'Anta (RN)ManLagoa D'anta (RN)-LopesOnneKWALEPuerto Gaitan. Meta, ColombiaConceicao dos Ouros (MG)UmudikePojuca (BA)RiversMedia Luna. Magdalena, ColombiaFadaInaBambiLukwakwaMalambo. Atlantico, ColombiaCornell BiotechChilimbaLoroRio FrioDoncelloPalmar de VarelaMogovolasSan Antonio de PalmitoSon LaMtwapaWarriNachingweaBulegeniVerdelandia (MG)-Brasnica Fazenda VilyamaZanzibarTapioca Development Institute (TDI), located in Huay Bong, Dan Khun Thot District, Nakhon RatchasimaPhu YenJamundi. Valle, ColombiaMalamboIkennePureza (RN)Puerto Lopez. Meta, ColombiaFarakobaHanoiNgomaKasuluSevillaItamaraju (BA)Ban Khao Luk Chang, Ta Phraya Sistrict, Sa Kaeo provinceCienagaS. de Quilichao. Cauca, ColombiaEl MiraEdoGuanambi (BA)-IF BaianoPolonuevoCruz Das Almas (BA) - UFRB CAMABSerra dos Aimores (MG)-Cachoeira da MataMahondaCarimagua. Meta, ColombiaLlanosVilla GarzonArmenia. Quindio, ColombiaMarataizes (ES)LiupoMonteria (UNICORDOBA). Cordoba, ColombiaLaje (BA)-Rio de Areia 1MigoriWakisoCruz das Almas (BA)-UFRB-PP1GbarpoluEketPuerto CaicedoBarranca De Upia. Casanare, ColombiaMansaLa Libertad. Meta, ColombiaLaberinto. Sucre, ColombiaCrossRiverMondomoPokuase-AccraLondrina (PR-Afapo)Teixeira de Freitas (BA)Mimoso do Sul (ES)Fumesua-KumasiCarimaguaBayelsaValledupar. Cesar, ColombiaPonta Pora (MS)-Assentamento ItamaratiMogincualBuenaventuraBouakeItiuba (BA)San PabloKisesa-MaguEl SaladoDewoinMomil. Cordoba, ColombiaBanteay Meanchey province Banteay MeancheyMulunguMsambweniNgabuCandelaria. Valle, ColombiaAlagoinhas (BA)-Boa UniaoNecocliKanoCaloto. Cauca, ColombiaCabuyaro. Meta, ColombiaSan MartinSoeng Sang is a district in the southeastern part of Nakhon Ratchasima provinceInhambupe (BA)-BotelhoThateng district, Sekong provinceBuga. Valle, ColombiaCantaclaroS. de QuilichaoCorozal. Sucre, ColombiaNational Corn and Sorghum Research Center (Suwan Farm), Kasetsart University Nakhon Ratchasima provinceLuruaco. Atlantico, ColombiaRepelon. Atlantico, ColombiaLa Libertad. Meta, ColombiaIlesaPend. , ColombiaVijes. Valle, ColombiaNaCRRI, Central UgandaLa UnionRokuprUnknownunknown2MbararaOtobiAugusto Correa (PA)MuhangaAzuaRwebitabaUbiajadavieNiaouliJamundiChamkar Leu districtBarranquillaAtivemeNgettaGranada. Meta, ColombiaCampecheJosIBARAPAEl Carmen de BolivarFrancisco PizarroSatiro Dias (BA)-Assentamento PapagaioPalmaseca. Valle, ColombiaLaje (BA)-Novo Horizonte 2ASan PedroCienaga De Oro. Cordoba, ColombiaMalam MadoriKumasiKamaConde (BA)-HumaitaSerereNecocli. Antioquia, ColombiaCorpoica PalmiraBetuliaLaje (BA)-Rio de Areia 2MocubaNigerDanyiTororoKizimbaniFonseca. Guajira, ColombiaOshogboPitalito. Atlantico, ColombiaLaberintoChambeziAdetaSantaguedaKakamegaTchadNsukkaCabuyaroKubwaIRRUALa LibertadLaje (BA)-Fazenda Sao JorgekaseseBaranoaPalmar de Varela. Atlantico, ColombiaMatazul. Meta, ColombiaBwangaKisumuPescador. Cauca, ColombiaLaje (BA)-RogerioSahagun. Cordoba, ColombiaChitalaAbidjanSabanalarga. Atlantico, ColombiaNgettaMokwaCarranzo. Cordoba, ColombiaMoralesSampuesChinuPouso Alegre (MG)Cajibio. Cauca, ColombiaLaje (BA)-Novo Horizonte 1Dong NaiYangambiNebbiPokuaseDaklakMorales. Cauca, ColombiaNyagatareMontanha (ES) - Fecularia ConquistaKibaaleBarranca De UpiaEl OveroArmero. Tolima, ColombiaCarepa. Antioquia, ColombiaSahagunLa Union. Sucre, ColombiaAlcobaca (BA)KilibaBetulia. Sucre, ColombiaAlbania. Sucre, ColombiaKaseseCIAT. Valle, ColombiaPendembuMsabahaBarrancabermeja. Santander, ColombiaChinu. Cordoba, ColombiaOritolossaVijesBela Vista de Goias (GO)Laje (BA)-Novo Horizonte 2BBolikham district, Bolikhamxay provinceCruz Das Almas (BA)-CNPMF-Area 2Namulonge-SendusuDamongoPatia. Cauca, ColombiaRestrepo. Meta, ColombiaNeivaCostaRepelonSanto TomasEntre Rios (BA)MIKOCHENICaribia. Magdalena, ColombiaChochoLaje (BA) - CapelaQuissama (RJ)-PMQ HortoKadunaweBom Jesus da Lapa (BA) - IF BaianoEkitiPitalito. Atlantico, ColombiaOgutaNong Yai is a district in the province ChonburiCandelariaMolineros. Atlantico, ColombiaPescadorNamulongeWenchi-BALa CumbreLaje (BA) - RailtonSanta Isabel do Para (PA)Santo Tomas. Atlantico, ColombiaMedia LunaMorogoroEl OlivoTauramena. Casanare, ColombiaCumaralValleduparFloridaMondomo. Cauca, ColombiaMotiloniaAguazul. Casanare, ColombiaLaje (BA)-Novo RumoCienaga De OroStung Treng Province, Stung TrengEuclides da Cunha (BA)Cruz Das Almas (BA) - UFRB - EstabuloAremasainLaje (BA)-Novo Horizonte 1Asuoiday, tanchau, tayninhKibosKamuliLa DoloresAlagoinhas (BA)COLDStore, RACK1, Shelf2, Cruz Das Almas (BA) CNPMF - CitrusRuziziPlainIkot AfangaBengouPivijay. Magdalena, ColombiaKogiAruaAgenbodeValenciaNatagaimaCampos dos Goytacazes (RJ)-UENFILONGABundibugyoEgbemaKakonkoMubendeSanto Amaro (BA)BarrancasCachoeira de Minas (MG)Dourados (MS)-UFGDDOKOLOCruz Das Almas (BA) - CNPMF - Area 1 (Ladeira maracuja)Los PalmitosGinebraNo Locations SelectedTrial Name:Location abbreviation will automatically be added as a prefix if multiple locations are selected.
Trial Type:Year:Planting Date:Plot Width (m):Plot Length (m):Field Size (ha):Plants per Plot:Inherits Treatment(s) From Plots:Creates plant entries for each plot. Ignore if not adding plant entries.
Assign row and column data to plants within plots?One plant per (row,column) coordinate. Rows and columns will be populated in a zigzag pattern. Row and column numbers start at 1 within each plot.
Number of rows per plot Number of columns per plot Description:Stock Type Being Evaluated in Trial:Select a stock type accession cross family_nameDesign Type:Completely Randomized Complete Block Resolvable Row-Column Doubly-Resolvable Row-Column Un-Replicated Diagonal Design Augmented Row-Column Alpha Lattice Lattice Augmented Modified Augmented Design Nursery/Greenhouse Split Plot Strip Plot Partially Replicated WestcottUsage HelpUse same randomization for all locations:First validate the form Continue to Next Step -
Design your trial layout
Which accessions will be in the field?
List of accessions to include (required):Which crosses will be in the field?
List of crosses to include (required):Which family names will be in the field?
List of family names to include (required):Name of Check 1:Name of Check 2:List of checks to include (required):List of checks to include (required):List of checks to include (required):List of checks to include. Checks list should be separate from accessions list. (optional):List of checks to include. Checks list should be accessions list. (optional):List of checks to include. Checks list should be accessions list. (optional):List of unreplicated accession (required):List of unreplicated cross (required):List of unreplicated family_name (required):List of replicated accession (required):List of replicated cross (required):List of replicated family_name (required):Need to create a list? Manage ListsNumber of rows in design:Number of columns in design :Number of times replicated accessions are replicated:Block sequence:Sub-block sequence:Default Number of Plants:Number of Plants:
Number of Columns (required):
Number of columns between two check columns (Optional):
Number of replicates (required):Number of blocks:Number of field rows (Required):Number of Columns (Required):Number of Columns per Block (2 or 4):Number of Rows Per Block (Optional):Treatment 1:Treatment 2:Treatment 3:Treatment 4:Add Another Treatment:+ TreatmentNumber of Plants Per Treatment (required):Show optional parameters:Column number per block:Number of field columns:Block size (required):Maximum block size (required):Which seedlots will you grow in the field?
This is optional and can be decided later. If you do not know exactly which seedlot packets you will be planting at this time, you can add this information on the Trial Detail Page after the trial has been saved in the database.List of seedlots for selected accessions (optional):Number of seeds per plot (required if seedlot list given):Need a list of seedlots for the selected accessions? Search Seedlots for Accessions
Continue to Next Step -
Is your trial linked with other field trials, genotyping plates, or crossing experiments in the database? If you are unsure, you can skip this. This information can be added from the trial detail page after the trial is saved.
Is this trial following-up a previous field trial?:No YesSelect the trial(s) which preceded this trial:If you go on to collect tissue samples for creating a 96 well plate for genotyping, when adding the genotyping plate (96 well plate layout) to the database you can use plot names or plant names or tissue sample names from this field trial. By doing so, we can create linkage between this field trial and the genotyping plate.
Will this trial be genotyped?:No YesIf you go on to perform crosses on this field trial, each cross can be linked to specific female and male plots. When you upload these crosses we can then automatically link this field trial to the crossing experiment in the database.
Will crosses be done on this trial?:No Yes
Continue to Next Step -
Specify the number of rows and columns for the entire field
By default field map display is set to serpentine and uses the block or rep number as row number.
If you do not want to create field map along with this trial, set 'Plot layout format' to 'select plot layout format'.
If you do not know exactly in which rows and columns you will end up planting the plots, do not provide this and go to the next step.
If you will plant your plots in an irregular (non-rectangular) layout, do not provide this and go to the next step.
You can upload the exact row and column information for your plots (in any layout shape) on the Trial Detail Page after you have created the trial in the database and actually planted the experiment.
Field map display:(comes with design)Field map display:Number of rows (required):Plot layout format:select plot layout format Zigzag(unserpentine) Serpentine
Continue to Next Step -
If you want to change the way in which plot names will be generated by the database
It is recommended to allow the database to create the plot prefixes, so leave the prefix blank unless necessary.
Custom plot naming/numbering:block based plot numbers (increment leading digit for every block)consecutive plot numbers throughout the blocksPlot prefix:Plot start number:1 101 1001Plot number increment:
Continue to Next Step -
Review the generated trial layout. Make sure to click Submit at the bottom of this page if you approve of the trial!
Check to confirm that your design looks good. If there are any problems you can redo the randomization step.
- Even Block Numbers (e.g. 2,4,...)
- Odd Block Numbers (e.g. 1,3,...)
- Checks
- Odd Rep Numbers (e.g. 1,3,...)
- Even Rep Numbers (e.g. 2,4,...)
No field map to display...
Redo RandomizationTrial Is Valid
The following trial will be added
Confirm (Saves Trial In Database)
Complete! Your trial was saved in the database.
The trial was saved successfully
- You may want to proceed to the trial detail page for the trial you just created.
- You can print barcodes for the plots or plants or tissue samples in this trial.
- You an add phenotypes for the plots or plants in this trial now.
The trial was saved to the database with no errors! Congrats Click Here
Complete! Your trial was saved in the database.
The trial was saved successfully
- You may want to proceed to the trial detail page for the trial you just created.
- You can print barcodes for the plots or plants or tissue samples in this trial.
- You an add phenotypes for the plots or plants in this trial now.
The trial was saved to the database with no errors! Congrats Click Here
Upload Treatment Spreadsheet
| File format information |
Simple treatment spreadsheets may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Template Information
Treatment spreadsheet must be uploaded in .xls or .xlsx excel file format
(tab-delimited text formats are NOT supported)
Create Treatment Spreadsheet for TrialRequired Data:
- Please click the above button to generate the required treatment spreadsheet. Note that treatment lists can be made just like trait lists.
Notes:
- For a hypothetical term "light intensity", "treatment name|treatment id"
should be written as "light intensity|EXPERIMENT_TREATMENT:00000XX". - Two or more treatments can be uploaded at the same time.
Simple and Detailed Spreadsheet Format:
- The "Simple" format requires only a column called 'observationunit_name' followed by your treatment columns. Other acceptable headers for the first column include: 'plot_name', 'subplot_name', 'plant_name', 'observationUnitName', 'plotName', 'sublotName', 'plantName'
- The "Detailed" format includes a special header as well as additional columns for design information.
Timestamps:
- To include timestamp information for your measurements, click the checkbox "Includes Timestamps".
- For timestamps, values should be recorded as "Value,Timestamp".
For no timestamps, values should be recorded as "Value". - Timestamp format must be YYYY-MM-DD HH:MM:SS-0000 or YYYY-MM-DD HH:MM:SS+0000
- Example with timestamps:
light intensity|EXPERIMENT_TREATMENT:00000XX 20,2016-04-28 16:30:40-0500 - Example without timestamps:
light intensity|EXPERIMENT_TREATMENT:00000XX 20
Partially Replicated Design Usage Help
Background:
Partially replicated designs have some treatments that are unreplicated and rely on replicated treatments to make the trial analysable. The design were described in Cullis et al. (2006). It is recommended that at least 20% of the experimental units are occupied by replicated treatments. The aim of these experiments is usually to select promising treatments from a set of replicated and unreplicated test treatments, with check and quality standard treatments providing the necessary replication overall to give a valid experiment. DiGGer (Coombes, 2002) was used to implement this design. DiGGer is a flexible tool for creating experimental designs that are efficient for specified blocking and correlation patterns. DiGGer package (http://www.austatgen.org/files/software/downloads) is an add-on for the statistical computing language and environment R (R Development Core Team, 2009).
Design Parameters:
The parameters will consider a sample partially replicated design trial with 200 unreplicated accessions, 119 accessions replicated 4 times, 26 rows in design, 26 columns in design, bock sequence of 13 by 2 (13, 2) i.e 2 blocks with each having 13 rows; sub-block sequence of block of 13 by 1 (13, 1) i.e 1 sub-block with each having 13 rows in each block.
List of Unreplicated Accession- You're expected to provide the list of unreplicated accessions in this selectbox. E.g. is a list of 200 accessions.
- List of replicated accessions should be provided in this selectbox. E.g. is a list of 119 accessions.
- Provide the number of rows you want to have in the design. E.g. 26 number of rows.
- Provide the number of columns you want to have in the design. E.g. 26 number of columns.
- Provide the number of times you want the replicated accessions to be replicated. E.g. 4
- The block sequence should reflect the blocking structure of your design. E.g. (13, 2), meaning the design has 2 blocks and each block has 13 rows.
- The sub-block sequence should reflect the sub-blocking structure of your design. E.g. (13, 1), meaning the design has 1 sub-block (column) and each sub-block has 13 rows.
NOTE:
- The product of the number of rows and columns in the design should equal the total number of plots.
- The sum of the unreplicated accessions and the replicated accessions (given the number of times it was replicated) should equal the total number of plots.
Upload Genotypes
-
Intro
-
Data Type
-
Genotyping Project
-
Genotyping Protocol
-
Genotype Info
-
Confirm
-
Complete
-
This workflow will guide you through uploading genotypes into the database
Select a genotyping project on the next screen. This project can represent a series of genotyping plates sent to a genotyping facilty.
Ideally the sample names in your VCF file will match sample names in genotyping plates in the database; however, the sample names in your file can also match accession names in the database.
Curently we support the VCF format, the Tassel HDF5 format, the Intertek CSV format, KASP data and SSR data for upload.
If you are uploading many files that used the same genotyping protocol, you can do so, and the database will ensure that the marker information is consistent across the genotyping data (e.g. the same reference, alternate, position, etc.).
Go to Next Step -
Select the type of genotyping data being uploaded
Type of genotyping data:Select data type VCF Tassel HDF5 Intertek KASP (csv) SSR
Go to Next Step -
Select the genotyping project or create a new one. A genotyping project is a specific genotyping event. You can have many genotyping projects under the same genotyping protocol to indicate that those genotyping events used the same markers.
Select Genotyping Project Name Description Breeding program Year Location Genotyping Facility My project is not here. Create a new one.
Genotyping Project Name:
Should match Vendor Project if you have oneGenotyping Facility:None Cornell IGD DArT Intertek IBRC Japan BGIBreeding Program:Year:Description:
Go to Next Step -
Provide info about the genotyping protocol used. The genotyping protocol represents a specific instance of how genotypes were called for a set of markers in a genotyping platform. Many genotyping projects can use the same genotyping protocol.
Select Protocol Name Header Description Number of Markers Protocol Description Reference Genome Species Sample Unit Create Date My protocol is not here. Create a new one.
Genotyping Protocol Name:Genotyping Protocol Reference Genome:Species:Assay TypeSelect assay type GBS KASP SSRDescription:Choose Sample Unit:Exported Tissue Sample Name: The sample names in your VCF are tissue_sample_names that already exist in genotyping plates (e.g. 96 well plates) or sampling trials in the database. The sample names in your VCF file can be the tissue_sample_name triple pipe joined to the accession_name (e.g. tissue_sample_name|||accession_name) or just simply the tissue_sample_name corresponding to the genotyping plate well or sampling trial sample. This is the recommended format.
Accession: The sample names are of accession names
Mixed Stocks: The sample names are a mix of accession names or plot names or sample names or other stock names. This is not recommended because it will lead to messy sample metadata.Location of Data Generation:Exported Tissue Sample Names Include Numbers Generated by Genotyping Facility (e.g. sample_name:IGD1001:09):
The generated number is separated from the tissue sample name in the database by a ':' separating character.
Go to Next Step -
Provide genotype information
Type of Genotype Data:Ignore any possible warnings and upload genotypes?:No YesFile format information
VCF format
Select VCF File:File format information
VCF format
Select Tassel HDF5 (.h5) File:File format information
Intertek format
Select Intertek SNP Result Grid File:Select Intertek SNP Information File:File format information
KASP data format
Select KASP Marker Information File (csv):Select KASP Result File (csv):File format information
SSR format
Select SSR File:
Check File Type Go to Next Step -
Finalize and submit your genotyping data
Add these missing stocks as new accessions?:No (currently disabled for safety)Submit -
Complete! Your genotyping data was saved in the database.
The genotyping data was saved successfully
Upload VCF Template Information
VCF is a tab separated format. If your VCF is very large (greater than 10GB), please consider converting it to an HDF5 (.h5) file using Tassel, and uploading the HDF5 formatted file instead.
Header:
The first row (header) must contain the following fields, followed by all genotyped sample names:
| #CHROM | POS | ID | REF | ALT | QUAL | FILTER | INFO | FORMAT | Sample names... |
- #CHROM (chromosome: An identifier from the reference genome pointing to a contig in the assembly file (cf. the ##assembly line in the header). All entries for a specific CHROM should form a contiguous block within the VCF file. The colon symbol (:) must be absent from all chromosome names to avoid parsing errors when dealing with breakends. (String, no white-space permitted, Required))
- POS (position: The reference position, with the 1st base having position 1. Positions are sorted numerically, in increasing order, within each reference sequence CHROM. It is permitted to have multiple records with the same POS. Telomeres are indicated by using positions 0 or N+1, where N is the length of the corresponding chromosome or contig. (Integer, Required) )
- ID ( identifier: Semi-colon separated list of unique identifiers where available. If this is a dbSNP variant it is encouraged to use the rs number(s). No identifier should be present in more than one data record. If there is no identifier available, then the missing value should be used. (String, no white-space or semi-colons permitted) )
- REF (reference base(s): Each base must be one of A,C,G,T,N (case insensitive). Multiple bases are permitted. The value in the POS field refers to the position of the first base in the String. For simple insertions and deletions in which either the REF or one of the ALT alleles would otherwise be null/empty, the REF and ALT Strings must include the base before the event (which must be reflected in the POS field), unless the event occurs at position 1 on the contig in which case it must include the base after the event; this padding base is not required (although it is permitted) for e.g. complex substitutions or other events where all alleles have at least one base represented in their Strings. If any of the ALT alleles is a symbolic allele then the padding base is required and POS denotes the coordinate of the base preceding the polymorphism. Tools processing VCF files are not required to preserve case in the allele Strings. (String, Required) )
- ALT (alternate base(s): Comma separated list of alternate non-reference alleles. These alleles do not have to be called in any of the samples. Options are base Strings made up of the bases A,C,G,T,N,*, (case insensitive) or a breakend replacement string as described in the section on breakends. The '*' allele is reserved to indicate that the allele is missing due to a upstream deletion. If there are no alternative alleles, then the missing value should be used. Tools processing VCF files are not required to preserve case in the allele String, except for IDs, which are case sensitive. (String; no whitespace, commas, or angle-brackets are permitted in the ID String itself) )
- QUAL (quality: Phred-scaled quality score for the assertion made in ALT. i.e. -10log10 prob(call in ALT is wrong). If ALT is '.' (no variant) then this is -10log10 prob(variant), and if ALT is not '.' this is -10log10 prob(no variant). If unknown, the missing value should be specified. (Numeric) )
- FILTER (filter status: PASS if this position has passed all filters, i.e. a call is made at this position. Otherwise, if the site has not passed all filters, a semicolon-separated list of codes for filters that fail. e.g. "q10;s50" might indicate that at this site the quality is below 10 and the number of samples with data is below 50% of the total number of samples. "0" is reserved and should not be used as a filter String. If filters have not been applied, then this field should be set to the missing value. (String, no white-space or semi-colons permitted) )
- INFO (additional information: (String, no white-space, semi-colons, or equals-signs permitted; commas are permitted only as delimiters for lists of values) INFO fields are encoded as a semicolon-separated series of short keys with optional values in the format: key=data[,data]. Arbitrary keys are permitted, although the following sub-fields are reserved (albeit optional):
- AA : ancestral allele
- AC : allele count in genotypes, for each ALT allele, in the same order as listed
- AF : allele frequency for each ALT allele in the same order as listed: use this when estimated from primary data, not called genotypes
- AN : total number of alleles in called genotypes
- BQ : RMS base quality at this position
- CIGAR : cigar string describing how to align an alternate allele to the reference allele
- DB : dbSNP membership
- DP : combined depth across samples, e.g. DP=154
- END : end position of the variant described in this record (for use with symbolic alleles)
- H2 : membership in hapmap2
- H3 : membership in hapmap3
- MQ : RMS mapping quality, e.g. MQ=52
- MQ0 : Number of MAPQ == 0 reads covering this record
- NS : Number of samples with data
- SB : strand bias at this position
- SOMATIC : indicates that the record is a somatic mutation, for cancer genomics
- VALIDATED : validated by follow-up experiment
- 1000G : membership in 1000 Genomes
- FORMAT (A format field is given specifying the data types and order (colon-separated alphanumeric String). This is followed by one field per sample, with the colon-separated data in this field corresponding to the types specified in the format. The first sub-field must always be the genotype (GT) if it is present. There are no required sub-fields. As with the INFO field, there are several common, reserved keywords that are standards across the community:
- GT : genotype, encoded as allele values separated by either of / or |. The allele values are 0 for the reference allele (what is in the REF field), 1 for the first allele listed in ALT, 2 for the second allele list in ALT and so on. For diploid calls examples could be 0/1, 1 | 0, or 1/2, etc. For haploid calls, e.g. on Y, male nonpseudoautosomal X, or mitochondrion, only one allele value should be given; a triploid call might look like 0/0/1. If a call cannot be made for a sample at a given locus, '.' should be specified for each missing allele in the GT field (for example './.' for a diploid genotype and '.' for haploid genotype). The meanings of the separators are as follows (see the PS field below for more details on incorporating phasing information into the genotypes):
- / : genotype unphased
- | : genotype phased
- DP : read depth at this position for this sample (Integer)
- FT : sample genotype filter indicating if this genotype was "called" (similar in concept to the FILTER field). Again, use PASS to indicate that all filters have been passed, a semi-colon separated list of codes for filters that fail, or '.' to indicate that filters have not been applied. These values should be described in the metainformation in the same way as FILTERs (String, no white-space or semi-colons permitted)
- GL : genotype likelihoods comprised of comma separated floating point log10-scaled likelihoods for all possible genotypes given the set of alleles defined in the REF and ALT fields. In presence of the GT field the same ploidy is expected and the canonical order is used; without GT field, diploidy is assumed. If A is the allele in REF and B,C,... are the alleles as ordered in ALT, the ordering of genotypes for the likelihoods is given by: F(j/k) = (k*(k+1)/2)+j. In other words, for biallelic sites the ordering is: AA,AB,BB; for triallelic sites the ordering is: AA,AB,BB,AC,BC,CC, etc. For example: GT:GL 0/1:-323.03,-99.29,-802.53 (Floats)
- GLE : genotype likelihoods of heterogeneous ploidy, used in presence of uncertain copy number. For example: GLE=0:-75.22,1:-223.42,0/0:-323.03,1/0:-99.29,1/1:-802.53 (String)
- PL : the phred-scaled genotype likelihoods rounded to the closest integer (and otherwise defined precisely as the GL field) (Integers)
- GP : the phred-scaled genotype posterior probabilities (and otherwise defined precisely as the GL field); intended to store imputed genotype probabilities (Floats)
- GQ : conditional genotype quality, encoded as a phred quality -10log10 p(genotype call is wrong, conditioned on the site's being variant) (Integer)
- HQ : haplotype qualities, two comma separated phred qualities (Integers)
- PS : phase set. A phase set is defined as a set of phased genotypes to which this genotype belongs. Phased genotypes for an individual that are on the same chromosome and have the same PS value are in the same phased set. A phase set specifies multi-marker haplotypes for the phased genotypes in the set. All phased genotypes that do not contain a PS subfield are assumed to belong to the same phased set. If the genotype in the GT field is unphased, the corresponding PS field is ignored. The recommended convention is to use the position of the first variant in the set as the PS identifier (although this is not required). (Non-negative 32-bit Integer)
- PQ : phasing quality, the phred-scaled probability that alleles are ordered incorrectly in a heterozygote (against all other members in the phase set). We note that we have not yet included the specific measure for precisely defining "phasing quality"; our intention for now is simply to reserve the PQ tag for future use as a measure of phasing quality. (Integer)
- EC : comma separated list of expected alternate allele counts for each alternate allele in the same order as listed in the ALT field (typically used in association analyses) (Integers)
- MQ : RMS mapping quality, similar to the version in the INFO field. (Integer)
If any of the fields is missing, it is replaced with the missing value. For example if the FORMAT is GT:GQ:DP:HQ then 0 | 0 : . : 23 : 23, 34 indicates that GQ is missing. Trailing fields can be dropped (with the exception of the GT field, which should always be present if specified in the FORMAT field). )
The exact format of each INFO sub-field should be specified in the meta-information (as described above). Example for an INFO field: DP=154;MQ=52;H2. Keys without corresponding values are allowed in order to indicate group membership (e.g. H2 indicates the SNP is found in HapMap 2). It is not necessary to list all the properties that a site does. )
Upload Intertek Template Information
Please use csv formatted files
For Intertek SNP Result Grid File:
The header must be:
| SampleName.LabID | All Marker Names In Separate Columns (e.g. marker name = S12_7926132) |
The SampleName.LabID column should contain the sample name (exported_tissue_sample_name or accession_name) and it must exist in the database already
For Intertek SNP Information File:The header must be:
| IntertekSNPID | CustomerSNPID | Reference | Alternate | Chromosome | Position | Optional: additional marker info can be included. Please see below. |
- Quality
- Filter
- Info
- Format
- Sequence
Upload Tassel HDF5 Template Information
Please use HDF5 (.h5) formatted files that work with Tassel
Uploading an HDF5 file is important when the size of the VCF grows greater than 10GB
Upload SSR Marker Info Template Information
Header:
The first row (header) must contain the following fields:
| marker_name | forward_primer | reverse_primer | annealing_temperature | product_sizes | sequence_motif | sequence_source | linkage_group |
- marker_name
- forward_primer
- reverse_primer
- annealing_temperature
- product_sizes
- sequence_motif
- sequence_source
- linkage_group
Upload SSR Marker Info Error
Success
SSR marker info was saved successfully. You can now proceed with SSR genotyping data upload.
Upload SSR Protocol (Marker Info)
| File format information |
Upload SSR Data Template Information
Example of SSR Data Spreadsheet:
| sample_name | s01 | s01 | s01 | s02 | s02 | s02 |
| 139 | 170 | 194 | 203 | 229 | 290 | |
| sample_A | 1 | 0 | 0 | 0 | 1 | 1 |
| sample_B | 0 | 0 | 0 | 1 | 0 | 0 |
| sample_C | 0 | 1 | 1 | 0 | 1 | 0 |
- s01 and s02 are marker names.
- 139, 170, 194 are product sizes generated by marker s01 and 203,229,290 are product sizes generated by marker s02.
- sample_A, sample_B, sample_C are accession names.
- "1" indicates the presence of PCR product.
- "0" indicates the absence of PCR product.
Upload KASP data Template Information
Please use csv formatted files
For KASP Marker Information File:
The header must be:
| MarkerName | Xallele | Yallele | Chromosome | Position | Optional: additional marker info can be included. Please see below. |
Optional columns: You can include additional marker information by selecting one or more column headers listed below. Please add the selected column(s) after "Position" column.
- Quality
- Filter
- Info
- Format
- Sequence
- FacilityMarkerName: if you are uploading genotyping data by using facility marker names, please include these names in the KASP marker information file using "FacilityMarkerName" header
Note: If your genotyping facility assigned facility marker names and facility sample names for the genotyping data generated, you have an option to directly use these facility names for uploading. After uploaded into database, the genotyping data will be automatically linked to the original marker names and sample names.
If you are uploading genotyping data using your marker names and sample names, the header must be:
| MarkerName | SampleName | SNPcall | Xvalue | Yvalue |
- MarkerName: Must exist in the marker information file. If you are uploading genotyping data using previously stored protocol, marker names must exist in the selected protocol.
- SampleName: Must exist in the database as uniquenames.
- SNPcall: Allele separated by ":" (for example A:G).
- Xvalue: raw data of X.
- Yvalue: raw data of Y.
If you are uploading genotyping data using facility marker names and facility sample names, the header must be:
| FacilityMarkerName | FacilitySampleName | SNPcall | Xvalue | Yvalue |
- FacilityMarkerName: Must exist in the marker information file.
- FacilitySampleName: Must exist in the database. You can create a link between each sample name and facility sample name by including facility sample name during uploading genotyping plates
- SNPcall: Allele separated by ":" (for example A:G).
- Xvalue: raw data of X.
- Yvalue: raw data of Y.
Upload Marker Metadata
-
Intro
-
Genotyping Protocol
-
Upload
-
Marker Metadata Information
This upload is used to add marker metadata and allele values to markers in an existing Genotyping Protocol.
Supported metadata include:
- A description of the marker (such as the phenotype derived from different allele values)
- Trait categories of phenotypes associated with the marker
- References to external databases with more information about the marker
- Allele values for individual alleles for each marker. For example, the 1RS marker can have the following allele values:
- Non-1RS
- 1RS:1BL
- 1RS:1AL
The first step will be to select the Genotyping Protocol that contains the markers. This Genotyping Protocol must already exist in the database.
The second step will be to upload the a file containing the metadata that are associated with each marker. The names of the markers in the file must match the marker names in the selected Genotyping Protocol.
Go to Next Step -
Select Genotyping Protocol
Select the Genotyping Protocol that contains the markers.
Go to Next StepSelect Protocol Name Header Description Number of Markers Protocol Description Reference Genome Species Sample Unit Create Date -
Header:
Upload Marker Metadata
The first row (header) must contain the following:
Required values:Marker Alias Description Category ...add additional Category columns, as necessary Allele ...add additional Allele columns, as necessary Reference ...add additional Reference columns, as necessary
Marker: the name of the marker (this must match the marker name in the selected Genotyping Protocol)
Allele: the name of a possible allele value for this marker (add as many Allele columns as necessary - or separate values in one column with a comma)
Optional values:
Alias: an alternate name for the marker (use this to provide a more human-friendly name for the marker)
Description: a description of the marker (its associated phenotype, etc)
Category: the name of the trait category that the marker belongs to (add as many Category columns as necessary - or separate values in one column with a comma)
Reference: a reference to an entity in an external database (such as a matching gene entry in GrainGenes). The format of this value should be: {database name}={entity name} (such as GrainGenes gene=Rht12 (Triticum)). The database name must already exist as an external database reference.
Marker Metadata may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Marker Metadata Alleles File:
Upload
Add Genotyping Plate
-
Intro
-
Genotyping Project
-
Basic Plate Info
-
Well Info
-
Trial Linkage
-
Confirm
-
This workflow will guide you through adding a genotyping plate in the database
Genotyping plates represent 96 or 384 well plates.
Each plate has a globally unique Plate ID.
Each well in the plate has a globally unique tissue sample ID.
The "contents" of each well can be either a tissue sample, plant name, subplot name, plot name, or accession name. This "source" name must be in the database already. This is useful if you provide a field trial entity (such as a plot or subplot or plant or tissue sample name), so that phenotypes and genotypes can be directly compared.
If you choose to submit your genotyping plate to a genotyping facility (Cornell IGD, Intertek, BGI, etc) we can generate the files they require for you. Please be aware of their requirements, such as blank well positions and concentrations.
In addition to sample ID, you have an option to include facility identifier for each well.
Go to Next Step -
Select a genotyping project
Genotyping projects are for grouping genotyping plates and/or genotyping data together. Genotyping Project should match Vendor Project if you have one.
If you need to create a genotyping project, click here
Once you have a genotyping project, go to Next Step -
Provide info about your plate
Genotyping Project Name:Genotyping Plate ID:
-In Coordinate App this is called "Plate Name"
-This is the globally unique name of the platePlate Format:96 Well 384 WellSample Type:DNA RNA TissueGenotyping Plate's Description (optional):Include Identifiers Generated by Genotyping Facility
(only for upload options):
Go to Next Step -
Provide information about the wells in your plate
Select One:Select a file format that you want to upload I am uploading a plate design I made in Excel I am uploading a Default Coordinate Android Application plate design I am uploading a Custom Coordinate Android Application plate design I need to design a completely new plate
You want to upload an existing plate layout
File format information
Spreadsheet format
Select Plate Layout XLSX File:You want to upload a Coordinate Android Application file.
File format information
Spreadsheet format
Select Coordinate CSV File:You want to upload a Custom Android Application file.
File format information
Spreadsheet format
Select Coordinate CSV File:You want to design a completely new plate.
- Select a list for the source material going into each well. Your list should be a one to one pairing to each well e.g. if you want to fill 95 wells you should supply a list of 95 elements.
- Note: From the most desirable to least desirable source observation unit you can choose: tissue samples, plants, subplots, plots, or accessions
Source Observation Unit List:[loading...]
Optional Blank Well: (Cornell IGD requires a specific well to be blank.)
Optional Well Concentration (ng/ul): (If you used the same conc for all wells)
Optional Well Volume (ul): (If you used the same vol for all wells)
Optional Tissue: (If used the same tissue for all wells)Leaf Root Stem Seed Fruit Tuber
Optional NCBI Taxonomy ID: (Official NCBI ID.)
Optional Extraction: (If used the same extraction for all wells)
Optional Person: (If same person prepared all wells.)
Optional Date: (If plated on same date. YYYY/MM/DD)
Optional Notes: (Additional notes for these wells.)
Go to Next Step -
Is your genotyping plate linked with field trials in the database? This information can also be added from the genotyping plate detail page once the trial is saved in the database.
If you provided us with information about where the tissue sample in each well originated (e.g. it came from a plot name or a subplot name or plant name or tissue sample name in a field trial), we will automatically create linkage between the field trial(s) and this genotyping plate.
Continue to Next Step -
Finalize and submit your genotyping plate
Automatic submission to the Genotyping Facility currently not working. You can submit it from the Genotyping Plate's detail page or download the information from the Genotyping Plate's detail page and submit it yourself after clicking Submit
Submit
Complete! Your genotyping plate was saved in the database.
The genotyping plate was saved successfully
- You may want to proceed to the genotyping plate detail page for the trial you just created.
- You can print barcodes for the plate and tissue samples.
Complete! Your genotyping plate was saved in the database.
The genotyping plate was saved successfully
- You may want to proceed to the genotyping plate detail page for the trial you just created.
- You can print barcodes for the plate and tissue samples.
Upload Template Information
File must be Excel file (.xls or .xlsx)
Header:
The first row (header) must contain the following:
| date | sample_id | well_A01 | row | column | source_observation_unit_name | ncbi_taxonomy_id | dna_person | notes | tissue_type | extraction | concentration | volume | is_blank |
Required fields:
- date (should be YYYY-MM-DD)
- sample_id (the unique identifier for the sample in the well)
- well_A01 (the position of the sample in the plate e.q. A10)
- row (the row position of the sample in the plate e.g. A)
- column (the column position of the sample in the plate e.g. 10)
- source_observation_unit_name (must exist in the database. the identifier of the origin material. in order of most desirable identifier to least desirable identifier that can be used here: tissue sample name, plant name, subplot name, plot name, accession name. For blank wells, you can write BLANK here and place a 1 in the is_blank column also.)
- tissue_type (must be either leaf, root, stem, seed, fruit or tuber)
- ncbi_taxonomy_id (NCBI taxonomy identifier)
- dna_person (the name of the person who prepared the well)
- notes (any additional notes on the well)
- extraction (free-text for the extraction method e.g. CTAB)
- concentration (concentration in ng/ul)
- volume (volume in ul)
- is_blank (indicates if well is blank. write 1 if blank, otherwise leave empty.)
- facility_identifier (if you would like to include facility identifiers in your genotyping plate layout, you can add facility identifiers in the last column with the header "facility_identifier")
Upload Template Information
File must be a CSV file (.csv)
(Excel format not supported)
Header:
The first row (header) must contain the following:
| date | plate_id | plate_name | sample_id | well_A01 | well_01A | tissue_id | dna_person | notes | tissue_type | extraction |
Required fields:
- date (should be YYYY-MM-DD)
- plate_id (an identifier for a grouping of plates. called "Genotyping Project Name" in genotyping plate submission form. e.g. NextGenCassava)
- plate_name (the unique name for the individual plate. called "Plate ID" in genotyping plate submission form. e.g. 18DNA00001)
- sample_id (the unique identifier for the sample in the well. e.g. 18DNA00001_A01)
- well_A01 (the position of the sample in the plate in this format A01)
- well_01A (the position of the sample in the plate in this format 01A)
- tissue_id (the identifier of the origin material. in order of most desirable identifier to least desirable identifier that can be used here: tissue sample name, plant name, subplot name, plot name, accession name. this can also say 'BLANK' to indicate a blank well.)
- dna_person (the name of the person who plated the individual sample. can be any name.)
- tissue_type (must be either leaf, root, or stem)
- notes (any additional notes on the well)
- extraction (free-text for the extraction method e.g. CTAB)
- facility_identifier (if you would like to include facility identifiers in your genotyping plate layout, you can add facility identifiers in the last column with the header "facility_identifier")
Upload Template Information
File must be a CSV file (.csv)
(Excel format not supported)
Header:
Note that tissue type will be set to 'leaf' if you use this upload type, since tissue type is not provided in the upload and tissue type is required for DaRT.
The first row (header) must contain the following:| Value | Column | Row | Identification | Person | Date |
Required fields:
- Value (the identifier of the origin material. e.g. 2018MyPlant0001. in order of most desirable identifier to least desirable identifier that can be used here: tissue sample name, plant name, subplot name, plot name, accession name. This can also say 'exclude' to indicate a BLANK)
- Column (the column position of the sample e.g. 10)
- Row (the row position of the sample e.g. A)
- Identification (free text)
- Person (the name of the person who plated the individual sample. can be any name.)
- Date (should be YYYY-MM-DD)
- Facility Identifier (if you would like to include facility identifiers in your genotyping plate layout, you can add facility identifiers in the last column with the header "Facility Identifier")
Upload Seedlot Inventory
-
Intro
-
File format
-
Upload inventory
-
Fix missing seedlots problem
-
Try submitting inventory again
-
What is a seedlot inventory?
- Seedlots represent physical seed in packets.
- This seed can be from crosses or for named accessions.
- Seedlots can have a specific location, box, weight(g), and count.
- Seedlots can belong to breeding programs and organizations.
- Seedlots can be used in trials (e.g. they were planted in a plot) and they can be harvested from a plot or plant (e.g. a cross was performed and seeds were collected.)
- A seedlot inventory consists of giving a location and current weight(g) to your seedlots. The seedlot name is the unique identifier for each seedlot and so should be encoded in a barcode on each seedlot packet.
- You can use the "Inventory" Android Application to scan seedlot barcodes and record weight. If you prefer you can create your own CSV file and upload that, if you do not want to use the Inventory Application. For info about the format of the file to upload, go to the next tab.
- It is also possible to manually enter a transaction by going to the seedlot detail page and clicking "Add New Transaction".
Go to Next Step -
Make sure you are collecting seedlot inventory in the following format
The "Seed Inventory" Android Application will export this same exact format by default.
Info about file format
Once you think your file matches, go to Next Step -
Select your file and upload seedlot inventory
Upload File (.csv):
Submit -
Fixing the missing seedlot(s) problem
- Seedlots must exist in the database prior to updating or adding inventory. The reason for this is that the inventory does not give information about the content (a named accession or a cross name) and this information is required for a seedlot to exist in the database. We also want to be careful about adding new seedlots into the database because we do not want data to be incorrectly linked to duplicates.
- When adding seedlots into the database, you can upload an Excel file or you can add seedlots one at a time.
- Upload Excel file
- Add One Seedlot
- Upload Excel file
Once all your seedlots are in the database Click Here
Seedlot Inventory Upload Error Messages
-
Submit your inventory again. You should have corrected all errors by now, but if not please take a look at the errors in the red box below. You can continue to modify your file and then click Upload until it works.
Upload Seedlot Inventory
There exist these problems in your file:
Finished! Your seedlot inventory is in the database
The seedlot inventory file was uploaded successfully
- You may want to proceed to the seedlot detail page(s) for the seedlot(s) you just updated.
- You can print barcodes for the seedlots.
Finished! Your seedlot inventory is in the database
The seedlot inventory file was uploaded successfully
- You may want to proceed to the seedlot detail page(s) for the seedlot(s) you just updated.
- You can print barcodes for the seedlots.
Upload Template Information
The first row (header) should contain the following:
| box_id | seed_id | inventory_date | inventory_person | weight_gram |
Required fields:
- box_id (the name of the box that the seedlot is in. also called box_name.)
- seed_id (unique identifier for the seedlot. must exist in the database. also called seedlot_name)
- inventory_date (a timestamp for when the seedlot was inventoried)
- inventory_person (the name of the person doing the inventory. can be any name. also called operator_name)
- weight_gram (the weight in grams of the seedlot)
OR
amount (number of materials in seedlot.)
Seedlot Inventory may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Upload Seedlots
-
Intro
-
What seedlots do you have?
-
File format
-
Upload seedlots
-
Fix errors in file
-
Try submitting seedlots again
-
What are seedlots?
- Seedlots represent physical plant materials in packets/containers.
- Plant material in a seedlot can be seed, root, clone, plant, tissue culture or gametophype.
- If you would like to set a default material type for seedlots, please contact us.
- These plant materials can be from crosses or for named accessions.
- Seedlots can have a specific location, box, weight_gram, and count.
- Seedlots can belong to breeding programs and organizations.
- Seedlots can be used in trials (e.g. they were planted in a plot) and they can be harvested from a plot or plant (e.g. a cross was performed and seeds were collected.)
Go to Next Step -
Seedlots fall into two categories
Select One:I have seedlots for named accessions I have seedlots harvested from crosses
Go to Next Step -
Make sure your file matches the correct file format
Information about file format for uploading seedlots of named accessions
Information about file format for uploading seedlots harvestedOnce you think your file matches, go to Next Step
-
Provide basic information about the seedlots and upload your file
Material Type:Breeding Program:Location of seedlot storage:Organization Name:Upload File:Upload File:Upload Seedlots
-
Fix all errors in your file
- Accessions must exist in the database prior to adding seedlots of them. The reason for this is that an accession can be exist in many seedlots and therefore exists as a separate entity in the database. We also want to be careful about adding new accessions into the database because we do not want incorrectly duplicated data.
- When adding accessions into the database, you can use either a list of accessions or an Excel file.
Add your accessions to the database
Once all your accessions are in the database Click Here
- Crosses must exist in the database before adding your seed lots. The reason for this is that a cross can produce many seed lots and so the cross must exists as a separate entity in the database. We also want to be careful about adding new crosses into the database because we do not want data to be incorrectly linked to duplicates.
- When adding crosses into the database, you can upload an Excel file or you can add seedlots one at a time.
- Upload Excel file
- Add One Cross
- Upload Excel file
Once all your crosses are in the database Click Here
Seedlot Upload Error Messages
-
Submit your seedlots again. You should have corrected all errors by now, but if not please take a look at the errors in the red box below. You can continue to modify your file and then click Upload until it works.
Upload Seedlots
There exist these problems in your file:
Finished! Your seedlots are now in the database
The seedlot file was uploaded successfully
- You may want to proceed to the seedlot detail page(s) for the seedlot(s) you just created.
- You can print barcodes for the seedlots.
Finished! Your seedlots are now in the database
The seedlot file was uploaded successfully
- You may want to proceed to the seedlot detail page(s) for the seedlot(s) you just created.
- You can print barcodes for the seedlots.
Upload Template Information For Named Accessions
The first row (header) should contain the following:
| seedlot_name | accession_name | operator_name | amount | weight_gram | description | box_name | quality | source |
- seedlot_name (must be unique)
- accession_name (must exist in the database. the accession_name is the unique identifier for the named genotype)
- operator_name (the name of the person who oversaw the inventory process. can be any name.)
- amount (number of materials in seedlot. can be provided in conjunction with weight_gram. must provide a value for amount or weight_gram or both.)
AND/OR
weight_gram (weight in grams of seedlot. can be provided in conjunction with amount. must provide a value for amount or weight_gram or both.) - box_name (the box name that the plant material is located in. can be any name.)
- description (information about why this seedlot is being added)
- quality (status of the seedlot, for example "ok", "moldy", "insect damage" etc.
- source (an alternate source, such as a plot, subplot, or plant identifier from which the seed was collected)
Seedlots may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Upload Template Information For Harvested Seedlots
The first row (header) should contain the following:
| seedlot_name | cross_unique_id | operator_name | amount | weight_gram | description | box_name | quality |
- seedlot_name (must be unique)
- cross_unique_id (must exist in the database. a cross_unique_id can represent a cross between accessions e.g. AxB, but a cross can also represent a cross between specific plots in the field if you have this information)
- operator_name (the name of the person who oversaw the inventory process. can be any name.)
- amount (number of materials in seedlot. can be provided in conjunction with weight_gram. must provide a value for amount or weight_gram or both.)
AND/OR
weight_gram (weight in grams of seedlot. can be provided in conjunction with amount. must provide a value for amount or weight_gram or both.) - box_name (the box name that the plant material is located in. can be any name.)
- description (information about why this seedlot is being added)
- quality (brief description of quality, e.g., "ok", "moldy", "insect damage", etc)
Seedlots may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Create New Seedlot
OR
Add Accessions
- Using Lists
- Uploading a File
Note: Use the fuzzy search to match similar names to prevent uploading of duplicate accessions. Fuzzy searching is much slower than regular search.
| File format information |
Note: Use the fuzzy search to match similar names to prevent uploading of duplicate accessions. Fuzzy searching is much slower than regular search. Only a curator can disable the fuzzy search.
When checked, add synonyms of existing accession entries to the synonyms already stored in the database. When not checked, remove any existing synonyms of existing accession entries and store only the synonyms in the upload file.
When checked, automatically create a new accession list with the accessions in your upload file.
Accessions may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Upload Accessions Template Information
The first row (header) must contain the accession_name and species_name columns. Additional information can be included by selecting optional column(s) (see below). :
| accession_name | species_name | population_name | synonym | description | BXW | Black Sigatoka | FOC-R1 | FOC-TR4 | Nematodes | PUI | Weevils | accession number | acquisition date | biological status of accession code | country of origin | donor | donor PUI | donor institute | genome_structure | institute code | institute name | introgression_backcross_parent | introgression_chromosome | introgression_end_position_bp | introgression_map_version | introgression_parent | introgression_start_position_bp | location_code | ncbbi_taxonomy_id | notes | organization | ploidy_level | seed source | state | transgenic | type of germplasm storage coode | variety | variety_release_id | year_of_cloning |
- The following fields can take comma-separated values to indicate there are several values for the accession: organization_name, synonym , BXW, Black Sigatoka, FOC-R1, FOC-TR4, Nematodes, PUI, Weevils, accession number, acquisition date, biological status of accession code, country of origin, donor, donor PUI, donor institute, genome_structure, institute code, institute name, introgression_backcross_parent, introgression_chromosome, introgression_end_position_bp, introgression_map_version, introgression_parent, introgression_start_position_bp, location_code, ncbbi_taxonomy_id, notes, organization, ploidy_level, seed source, state, transgenic, type of germplasm storage coode, variety, variety_release_id, year_of_cloning
- accession_name (must be unique)
- species_name (must exist in the database)
- description - a free text description of the stock.
- population_name (a population is a grouping of accessions. If the population already exists in the database, the accession will be added to it; otherwise, a new population will be created). Multiple populations can be specified, using the pipe symbol (|) as the separator (for example, pop1|pop2|pop3)
- synonym (an accession can be known by many names including local popular names. a synonym name can be used instead of the accession_name throughout the database; because of this, synonyms must themselves be unique. e.g. accession_synonym1,accession_synonym001)
- BXW (no definition available)
- Black Sigatoka (no definition available)
- FOC-R1 (no definition available)
- FOC-TR4 (no definition available)
- Nematodes (no definition available)
- PUI (no definition available)
- Weevils (no definition available)
- accession number (no definition available)
- acquisition date (no definition available)
- biological status of accession code (no definition available)
- country of origin (no definition available)
- donor (no definition available)
- donor PUI (no definition available)
- donor institute (no definition available)
- genome_structure (no definition available)
- institute code (no definition available)
- institute name (no definition available)
- introgression_backcross_parent (no definition available)
- introgression_chromosome (no definition available)
- introgression_end_position_bp (no definition available)
- introgression_map_version (no definition available)
- introgression_parent (no definition available)
- introgression_start_position_bp (no definition available)
- location_code (no definition available)
- ncbbi_taxonomy_id (no definition available)
- notes (no definition available)
- organization (no definition available)
- ploidy_level (no definition available)
- seed source (no definition available)
- state (no definition available)
- transgenic (no definition available)
- type of germplasm storage coode (no definition available)
- variety (no definition available)
- variety_release_id (no definition available)
- year_of_cloning (no definition available)
Accessions may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Optional columns may be left out, if not used in your data.
Accessions to be Added
Population name for added accessions (optional)
Organization name for added accessions (optional)
The following accessions are new and will be added to the database:
Fuzzy Matches
Found Accessions
Accessions Saved
Upload Crosses
-
Intro
-
Crossing experiment
-
Upload your crosses
-
Introduction
- Crosses can be of different types (biparental, self, open, backcross, sib, polycross, bulk, bulk_open, bulk_self, doubled_haploid, or dihaploid_induction)
- cross type descriptions:
- biparental: An individual plant pollinated by another individual plant.
- self: A self pollinated individual plant.
- open: An individual plant pollinated by a group of plants or open pollinated (pollen may be from a group with known or unknown members).
- backcross: An individual plant pollinated by one of its parents. Cross Unique ID can be used as one of the parents.
- sib: Mating between individuals that have at least one parent in common. Generally between two individuals within the same plot.
- polycross: Mating between individual female parent from a population and the corresponding male population.
- bulk: A group of plants (usually a related family) pollinated by an individual plant (between a female population and a male accession).
- bulk_open: A group of plants (usually a related family) that are pollinated by another group of plants or open pollinated (between a female population and a male population or unknown male parent).
- bulk_self: A group of plants (usually a related family) that are self pollinated (each individual selfed, not combined pollen).
- doubled_haploid: Plants derived from doubling the chromosome number of haploid tissue.
- dihaploid_induction: Plants derived from reducing the chromosome set from tetraploid to diploid.
- An individual cross can be linked to a female plot or plant, as well as a male plot or plant.
- A cross can have a number of properties associated to it, such as number of flowers, pollination date, etc.
- A cross can produce seed, which goes into a seedlot.
- A cross can ultimately produce progeny, which then become named accessions in the database.
Go to Next Step -
If you are uploading an Intercross file and using auto-generated cross unique IDs, please use manage Intercross section
Select a crossing experiment for your crosses
Crossing experiments are for grouping crosses together. The grouping is most often done for crosses derived from the same field trial, the same year, or for crosses that have the same breeding objective.
If you need to create a new crossing experiment, click here
If you already have a crossing experiment, go to Next StepYou are uploading crosses for crossing experiment:
Go to Next Step -
Enter basic information about the crosses and upload your file
Breeding Program:
Crossing Experiment:Crossing Experiment:File format information
Spreadsheet format
Upload File:Crosses may be uploaded using any of the supported file types: MS Excel (.xls or .xlsx), comma-separated file (.csv), LibreOffice / OpenOffice OpenDocument spreadsheet (.ods), tab-delimited file (.txt or .tsv), or semicolon-separated file (.ssv).
Upload File
Finished! Your crosses are now in the database
The crosses file was uploaded successfully
- You may want to proceed to the cross detail page(s) for the cross(es) you just created.
- You can print barcodes for the crosses.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
The crosses were saved to the database with no errors! Congrats Click Here
Finished! Your crosses are now in the database
The crosses file was uploaded successfully
- You may want to proceed to the cross detail page(s) for the cross(es) you just created.
- You can print barcodes for the crosses.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
The crosses were saved to the database with no errors! Congrats Click Here
Upload Crosses File Error
Template Information
Header:
To set up crosses in the database, please provide required information. The first row (header) must contain the following:
| cross_unique_id | cross_combination | cross_type | female_parent | male_parent |
- cross_unique_id (must NOT exist in the database)
- cross_combination (required in the header, but value for cross combination (e.g. female accession/male accession) may be left blank)
- cross_type (must be one of the following: biparental, self, open, sib, polycross, backcross, bulk, bulk_open, bulk_self, doubled_haploid, dihaploid_induction)
- biparental: An individual plant pollinated by another individual plant.
- self: A self pollinated individual plant.
- open: An individual plant pollinated by a group of plants or open pollinated (pollen may be from a group with known or unknown members).
- backcross: An individual plant pollinated by one of its parents.
- sib: Mating between individuals that have at least one parent in common. Generally between two individuals within the same plot.
- polycross: Mating between individual female parent from a population and the corresponding male population.
- bulk: A group of plants (usually a related family) pollinated by an individual plant (between a female population and a male accession).
- bulk_open: A group of plants (usually a related family) that are pollinated by another group of plants or open pollinated (between a female population and a male population or unknown male parent).
- bulk_self: A group of plants (usually a related family) that are self pollinated (each individual selfed, not combined pollen).
- doubled_haploid: Plants derived from doubling the chromosome number of haploid tissue.
- dihaploid_induction: Plants derived from reducing the chromosome set from 4 to 2.
- female_parent: Female parent names must exist as uniquenames in the database, can be accession, plot, plant or population stock type.
- male_parent: Required in the header, but value may be left blank for most cross types. Must be specified for biparental, sib, backcross, polycross and bulk cross types. When specified, male parent names must exist as uniquenames in the database, can be accession, plot, plant or population stock type.
- objective
- female_focus_trait
- male_focus_trait
- female_source_trial
- male_source_trial
- After cross unique ids are stored in the database, you can add field crossing data (e.g. pollination date, total number of flowers pollinated, total number of fruits set) or progenies to each cross unique id.
- Field crossing data and progenies can be uploaded via links in crossing experiment detail page or can be added directly in each cross detail page.
Add New Cross
-
Intro
-
Crossing Experiment
-
Enter cross information
-
Enter parentage information
-
Additional cross info
-
What is a cross?
- The Cross Tool can track any pollinations in a breeding program.
- Each cross has a globally unique cross id.
- Supported cross types are: biparental, self, open, backcross, sib, polycross, bulk, bulk_self, bulk_open, doubled_haploid, or dihaploid_induction
- For an open pollinated cross, the cross can be defined as between female accession A and male population P1 (populations in the database are defined strictly as groups of accessions). If the male parent is not known, it can be left blank.
- For backcross cross type, cross unique id can be used as one of the parents.
- An individual cross can be linked to the specific female plot or plant, as well as to the specific male plot or plant.
- A cross can have other data associated to it, such as number of flowers, pollination date, etc.
- Seed produced by a cross can be managed using a seedlot.
- Progenies from a cross can become named accessions in the database.
Go to Next Step -
Select a crossing experiment
Crossing experiments are for grouping crosses together. The grouping is most often done for crosses derived from the same field trial, the same year, or for crosses that have the same breeding objective.
If you need to create a crossing experiment, click here
Once you have a crossing experiment, go to Next Step -
Enter basic information about the cross
Cross type information
Descriptions of cross typesBreeding Program:
Crossing Experiment:
Cross Unique ID:
Cross Combination (optional):
Cross Type:Select a cross type biparental self open pollinated backcross sib bulk bulk selfed bulk and open pollinated doubled haploid dihaploid induction polycross reciprocal multicross
Go to Next Step -
Enter basic information about the cross
Female Parent:
Male Parent:
Selfed Parent:
Female Parent:
Male Population: (optional)
Female Population:
Male Parent:
Selfed Population:
Female Population:
Male Population: (optional)
Doubled Haploid Parent:
Dihaploid induction Parent:
Accessions to use in Polycross:
Accessions to use in Reciprocal cross:
Multicross Female Parents:
Multicross Male Parents:
Optional: If you choose to record exact cross parents, you can do so.
Field Trial:Search Plots/Plants
Female Plot/Plant:Enter trial name first
Male Plot/Plant:Enter trial name first
Optional: If you choose to record exact cross female parent, you can do so.
Field Trial:Search Plots/Plants
Female Plot/Plant:Enter trial name first
Go to Next Step -
If you would like to add auto-generated progeny names for this cross, you can add it here
Optional:
Add New Accessions for Progeny:Number of progeny:Use Prefix and/or Suffix:Prefix:Suffix:
Submit Cross
Finished! Your cross is now in the database
The cross was added successfully
- You may want to proceed to the cross detail page for the cross you just created.
- You can print barcodes for the cross.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
Finished! Your cross is now in the database
The cross was added successfully
- You may want to proceed to the cross detail page for the cross you just created.
- You can print barcodes for the cross.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
Template Information
Individual Crosses:
biparental: An individual plant pollinated by another individual plant.
self: A self pollinated individual plant.
open pollinated: An individual plant pollinated by a group of plants or open pollinated (pollen may be from a group with known or unknown members).
backcross: An individual plant pollinated by one of its parents.
sib: Mating between individuals that have at least one parent in common. Generally between two individuals within the same plot.
bulk: A group of plants (usually a related family) pollinated by an individual plant.
bulk selfed: A group of plants (usually a related family) that are self pollinated (each individual selfed, not combined pollen).
bulk and open pollinated: A group of plants (usually a related family) that are pollinated by another group of plants or open pollinated (pollen may be from a group with known or unknown members).
doubled haploid: Plants derived from doubling the chromosome number of haploid tissue.
dihaploid induction: Plants derived from a chromosome reduction from tetraploid to diploid
Group of Crosses:
polycross: Creates a group of open pollinated crosses. Each accession in the selected list becomes the female parent in an open cross, and all the members of the list grouped together form the male parent.
reciprocal: Creates a group of biparental crosses. Starting with a list of accessions, all possible biparental cross combinations are made between them.
multicross: Creates a group of biparental crosses. Starting with a list of maternal accessions and a list of paternal accessions, direct crosses are made in order.
Success
The cross or crosses were saved successfully.
Add New Crossing Experiment
-
Intro
-
Add a crossing experiment
-
What are crossing experiments?
Crossing experiments group crosses. The grouping can reflect crosses done in the same field trial, crosses in a breeding program in a given year, or crosses that have the same breeding objective. This grouping can be used to encapsulate all the crosses done in a crossing block field trial that you have saved in the database (e.g. in Manage Trials your crossing block will appear as a field trial with plots)
Go to Next Step -
Enter basic information about the crossing experiment
Crossing Experiment Name:
Breeding Program:Select Breeding Program 5CPBTICARICHCIATCIP-genebankCNRACornellCSIR-CRIEmbrapaIDIAFIITAINERA_IITA_DRCISABUITCKALROKUNaCRRINRCRIRayongSLARITARIUACUHUNILA-IndonesiaZARI
Location of crossing experiment:Select Location RestrepoIgbariamGranadaFlorenciabwangaMvuaziNaliendeleKokrokoChokweCalabarJaguaripe (BA) - Fazenda Esperan�aCorozal. Sucre, ColombiaAgborSuakokoKibahaIshiaguBarahonaNjalaSotoubouaBuenos AiresAlbaniaItanhem (BA)IlorinAcacias. Meta, ColombiaVerdelandia (MG)-Brasnica Fazenda OrienteCIATDarien. Valle, ColombiaEl Espinal. Tolima, ColombiaTerra Alta (PA)[Computation]Puerto Caicedo. Putumayo, ColombiaFlorestal (MG) - UFV Campus FlorestalLUWEEROMatazulAkwa IbomLaje (BA)-RoqueEjuraVilla Garzon. Putumayo, ColombiaLuruacoHomboloQuilcace. Cauca, ColombiaTumacoCaribiaOvejasMomilLomeMukonoSabanagrandeBlamaSao Mateus (ES)KiggumbaNjuliMakokaZariaIITA-DARArmeroZomboAnlong Veng District, Oddar Meanchey provinceMutata. Antioquia, ColombiaAguazulValencia. Cordoba, ColombiaQuang NgaiAgustin CodazziMakeniKabalaNametilPalmiraBolivarKwaraKazilamuyagaTamalameque. Cesar, ColombiaBaranoa. Atlantico, ColombiaEsplanada (BA) - CachoeiraUkereweNhacoongoIbadanLaje (BA)-GaviaoKaomaMangabeira (BA)-IF BaianoGairoBuginyanyaMarukuMtwapa2an co chauthanh, tayninhVarzedo (BA)UmbeluziSao Francisco de Itabapoana (RJ)-Industria Dona ChicaBukembaCampos Novos Paulista (SP)-Tereos SyralCIAT. Valle, ColombiaOgoniInharrimeBulingaUyoEmbuBarrancabermejaKabangweDarienCereteFumesuaSiayaMacapa (AP)SabanalargaEl Overo. Valle, ColombiaLa Colina. Sucre, ColombiaCaldonoPallisaSabanalarga. Atlantico, ColombiaKhao Hinsorn Research Center, Kasetsart University, Chachoengsao provinceRatanak Mondul district, Battambang provinceMasakaEl Olivo. Cordoba, ColombiaApiayVitoria da Conquista (BA) - Fecularia ConquistaKaberamaidoSulutiSan Vicente. Santander, ColombiaMontenegro. Quindio, ColombiaTouros (RN)-PrataBusiaAremasain. Guajira, ColombiaunspecifiedMutataChiengiSanta CruzAbujaUniversity of HawaiiAkureOhawuCarepaTay NinhLirakasuluApiay. Meta, ColombiaBugaPetrolina (PE)-UNIVASFPatiaMichikichiniItasyAgo-OwuMkondeziPopayanDoncello. Caqueta, ColombiaDivoPajau. Brasil, BrazilQuilcaceFlorencia. Caqueta, ColombiaTangakonaMontenegroBundaPuerto GaitanBarranquilla. Atlantico, ColombiaCorozalPinheiros (ES)MontanitaChitedzeJeddoLao NgamSikhiu is a district (amphoe) in the western part of Nakhon Ratchasima provinceCienaga. Magdalena, ColombiaTol�Marechal Candido Rondon (PR)-ATIMOPEl EspinalHoma BayArmeniaTESTSanto Tomas. Atlantico, ColombiaMkurangaKisesaAssin FosuYopal. Casanare, ColombiabadagryObuduNaphokLa Dolores. Valle, ColombiaSenjehRufunsaUkiriguruSampues. Sucre, ColombiaCajibioCora��o de Maria (BA)GongoniLa HormigaRakaiPalmasecaLoricaCruz das Almas (BA)-UFRB-CandealMargibiAKUMADANTracuateua (PA)Tol�viejoPopayan. Cauca, ColombiaAcaciasTauramenaKipopoAgbarhoNgandajikaSan Miguel. Sucre, ColombiaOrito. Putumayo, ColombiaPuerto Asis. Putumayo, ColombiaCumaral. Meta, ColombiaRubiriziBuikweKalomoSan Martin. Meta, ColombiaCerete. Cordoba, ColombiaMityanaOsunKiyakaPivijaySinceMontanita. Sucre, ColombiaConde (BA)-CanguritoNyankpalaVitoria da Conquista (BA)Prado (BA)MbuniHung YenLaje (BA) - Fazenda Sombra VerdeDeltaBoyce Thompson InstitutePitalitoKasinthukaPuerto AsisWenchiSan VicenteCaracoli. Atlantico, ColombiaKebbiAlupeCapanema (PA)RubonaChatoCalotoUsiacuriibadanSanta Cruz. Atlantico, ColombiaLa Hormiga. Putumayo, ColombiaMonteriaLaje (BA)-Rio de Areia 1Rio Frio. Magdalena, ColombiaEl Carmen. Bolivar, ColombiaTeresina (PI)OrtegaIresiYopalFonsecaCaracoliEl Salado. Cordoba, ColombiaPuerto LopezLagoa D'Anta (RN)ManLagoa D'anta (RN)-LopesOnneKWALEPuerto Gaitan. Meta, ColombiaConceicao dos Ouros (MG)UmudikePojuca (BA)RiversMedia Luna. Magdalena, ColombiaFadaInaBambiLukwakwaMalambo. Atlantico, ColombiaCornell BiotechChilimbaLoroRio FrioDoncelloPalmar de VarelaMogovolasSan Antonio de PalmitoSon LaMtwapaWarriNachingweaBulegeniVerdelandia (MG)-Brasnica Fazenda VilyamaZanzibarTapioca Development Institute (TDI), located in Huay Bong, Dan Khun Thot District, Nakhon RatchasimaPhu YenJamundi. Valle, ColombiaMalamboIkennePureza (RN)Puerto Lopez. Meta, ColombiaFarakobaHanoiNgomaKasuluSevillaItamaraju (BA)Ban Khao Luk Chang, Ta Phraya Sistrict, Sa Kaeo provinceCienagaS. de Quilichao. Cauca, ColombiaEl MiraEdoGuanambi (BA)-IF BaianoPolonuevoCruz Das Almas (BA) - UFRB CAMABSerra dos Aimores (MG)-Cachoeira da MataMahondaCarimagua. Meta, ColombiaLlanosVilla GarzonArmenia. Quindio, ColombiaMarataizes (ES)LiupoMonteria (UNICORDOBA). Cordoba, ColombiaLaje (BA)-Rio de Areia 1MigoriWakisoCruz das Almas (BA)-UFRB-PP1GbarpoluEketPuerto CaicedoBarranca De Upia. Casanare, ColombiaMansaLa Libertad. Meta, ColombiaLaberinto. Sucre, ColombiaCrossRiverMondomoPokuase-AccraLondrina (PR-Afapo)Teixeira de Freitas (BA)Mimoso do Sul (ES)Fumesua-KumasiCarimaguaBayelsaValledupar. Cesar, ColombiaPonta Pora (MS)-Assentamento ItamaratiMogincualBuenaventuraBouakeItiuba (BA)San PabloKisesa-MaguEl SaladoDewoinMomil. Cordoba, ColombiaBanteay Meanchey province Banteay MeancheyMulunguMsambweniNgabuCandelaria. Valle, ColombiaAlagoinhas (BA)-Boa UniaoNecocliKanoCaloto. Cauca, ColombiaCabuyaro. Meta, ColombiaSan MartinSoeng Sang is a district in the southeastern part of Nakhon Ratchasima provinceInhambupe (BA)-BotelhoThateng district, Sekong provinceBuga. Valle, ColombiaCantaclaroS. de QuilichaoCorozal. Sucre, ColombiaNational Corn and Sorghum Research Center (Suwan Farm), Kasetsart University Nakhon Ratchasima provinceLuruaco. Atlantico, ColombiaRepelon. Atlantico, ColombiaLa Libertad. Meta, ColombiaIlesaPend. , ColombiaVijes. Valle, ColombiaNaCRRI, Central UgandaLa UnionRokuprUnknownunknown2MbararaOtobiAugusto Correa (PA)MuhangaAzuaRwebitabaUbiajadavieNiaouliJamundiChamkar Leu districtBarranquillaAtivemeNgettaGranada. Meta, ColombiaCampecheJosIBARAPAEl Carmen de BolivarFrancisco PizarroSatiro Dias (BA)-Assentamento PapagaioPalmaseca. Valle, ColombiaLaje (BA)-Novo Horizonte 2ASan PedroCienaga De Oro. Cordoba, ColombiaMalam MadoriKumasiKamaConde (BA)-HumaitaSerereNecocli. Antioquia, ColombiaCorpoica PalmiraBetuliaLaje (BA)-Rio de Areia 2MocubaNigerDanyiTororoKizimbaniFonseca. Guajira, ColombiaOshogboPitalito. Atlantico, ColombiaLaberintoChambeziAdetaSantaguedaKakamegaTchadNsukkaCabuyaroKubwaIRRUALa LibertadLaje (BA)-Fazenda Sao JorgekaseseBaranoaPalmar de Varela. Atlantico, ColombiaMatazul. Meta, ColombiaBwangaKisumuPescador. Cauca, ColombiaLaje (BA)-RogerioSahagun. Cordoba, ColombiaChitalaAbidjanSabanalarga. Atlantico, ColombiaNgettaMokwaCarranzo. Cordoba, ColombiaMoralesSampuesChinuPouso Alegre (MG)Cajibio. Cauca, ColombiaLaje (BA)-Novo Horizonte 1Dong NaiYangambiNebbiPokuaseDaklakMorales. Cauca, ColombiaNyagatareMontanha (ES) - Fecularia ConquistaKibaaleBarranca De UpiaEl OveroArmero. Tolima, ColombiaCarepa. Antioquia, ColombiaSahagunLa Union. Sucre, ColombiaAlcobaca (BA)KilibaBetulia. Sucre, ColombiaAlbania. Sucre, ColombiaKaseseCIAT. Valle, ColombiaPendembuMsabahaBarrancabermeja. Santander, ColombiaChinu. Cordoba, ColombiaOritolossaVijesBela Vista de Goias (GO)Laje (BA)-Novo Horizonte 2BBolikham district, Bolikhamxay provinceCruz Das Almas (BA)-CNPMF-Area 2Namulonge-SendusuDamongoPatia. Cauca, ColombiaRestrepo. Meta, ColombiaNeivaCostaRepelonSanto TomasEntre Rios (BA)MIKOCHENICaribia. Magdalena, ColombiaChochoLaje (BA) - CapelaQuissama (RJ)-PMQ HortoKadunaweBom Jesus da Lapa (BA) - IF BaianoEkitiPitalito. Atlantico, ColombiaOgutaNong Yai is a district in the province ChonburiCandelariaMolineros. Atlantico, ColombiaPescadorNamulongeWenchi-BALa CumbreLaje (BA) - RailtonSanta Isabel do Para (PA)Santo Tomas. Atlantico, ColombiaMedia LunaMorogoroEl OlivoTauramena. Casanare, ColombiaCumaralValleduparFloridaMondomo. Cauca, ColombiaMotiloniaAguazul. Casanare, ColombiaLaje (BA)-Novo RumoCienaga De OroStung Treng Province, Stung TrengEuclides da Cunha (BA)Cruz Das Almas (BA) - UFRB - EstabuloAremasainLaje (BA)-Novo Horizonte 1Asuoiday, tanchau, tayninhKibosKamuliLa DoloresAlagoinhas (BA)COLDStore, RACK1, Shelf2, Cruz Das Almas (BA) CNPMF - CitrusRuziziPlainIkot AfangaBengouPivijay. Magdalena, ColombiaKogiAruaAgenbodeValenciaNatagaimaCampos dos Goytacazes (RJ)-UENFILONGABundibugyoEgbemaKakonkoMubendeSanto Amaro (BA)BarrancasCachoeira de Minas (MG)Dourados (MS)-UFGDDOKOLOCruz Das Almas (BA) - CNPMF - Area 1 (Ladeira maracuja)Los PalmitosGinebra
Year:
Description:
Submit
Finished! Your crossing experiment is now in the database
Crossing experiment was added successfully
- You may want to proceed to the crossing experiment detail page you just created.
- You can add or upload crosses into your crossing experiment as they become available.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
Finished! Your crossing experiment is now in the database
Crossing experiment was added successfully
- You may want to proceed to the crossing experiment detail page you just created.
- You can add or upload crosses into your crossing experiment as they become available.
- You can add crossing information as it becomes available (e.g. number of seeds, progeny, etc).
Cassava (Manihot esculenta), a major staple crop, is the main source of calories for 500 million people across the globe. No other continent depends on cassava to feed as many people as does Africa. Cassava is indispensable to food security in Africa. It is a widely preferred and consumed staple, as well as a hardy crop that can be stored in the ground as a fall-back source of food that can save lives in times of famine. Despite the importance of cassava for food security on the African continent, it has received relatively little research and development attention compared to other staples such as wheat, rice and maize. The key to unlocking the full potential of cassava lies largely in bringing cassava breeding into the 21st century. [More...]
Cassavabase Mirror at IITA (Nigeria)
Cassava Descriptors
HTPG project
Intertek sample form and tutorial
For all questions about Cassava (phenotyping, genotyping, population genetics) subscribe to the cassava-discussion@cassavabase.org mailing list!
Global Cassava Partnership (GCP)
Int'l Society for Tropical Root Crops (ISTRC)
Integrated Breeding Platform
CassavaCyc
RIKEN Cassava Database
Cassavabiotech.org (CAS, Shanghai, China)
Cassavagenome.org
GOBii project
Cassava Disease Net
Plant Village
Cassava in tropical Africa a reference manual
Please Note: Website Data Usage Policy
Cassavabase adheres to the Toronto Agreement on prepublication data release.
All data deposited on cassavabase adheres to the Toronto Agreement on prepublication data release. To foster transparent and accessible data sharing culture, in accordance with the Toronto Agreement, all data deposited on cassavabase will be made public immediately. Data producers can provide information on the data they deposit, including planned analyses and publication timeline information, to indicate their publication intentions. Data users are expected to respect scientific etiquette and allow data producers the first global analyses of their data set, and should be aware that pre-publication data may not have been subject to full quality control and peer review, so caution must be applied when utilizing these data. More information is available on the data usage policy page.| CassavaBase Forum |
| Cassava Wiki |
| Cassava Discussion Mailing List |
Time: Sunday, Jan 11, 2026, 8:00 AM - 10:10 AM
Featured Publication
Your Lists
Public Lists
List Contents
List Validation Report: Failed
Elements not found:
Optional: Add Missing Accessions to A List
Mismatched case
Adjust Case
Multiple mismatched case
Items listed here have mulitple case mismatches and must be fixed manually. If accessions need to be merged, contact the database directly.
List elements matching a synonym
Replace synonyms with corresponding DB name
Multiple synonym matches
Fuzzy Search Results
Synonym Search Results
Available Seedlots
| Accessions | Seedlots | |||||
|---|---|---|---|---|---|---|
| Select/Deselect All | Breeding Program | Seedlot Name | Contents | Seedlot Location | Count | Weight(g) |
List Comparison
Your Datasets
Public Datasets
Dataset Contents
Dataset Validation Failed
Elements not found:
Your Calendar
Having trouble viewing events on the calendar?
Are you associated with the breeding program you are interested in viewing?
Add New Event
Event Info
| Attribute | Value |
|---|---|
| Project Name: | |
| Start Date: | |
| End Date: | |
| Event Type: | |
| Event Description: | |
| Event Web URL: |
Edit Event
Login
Forgot Username
Get Username(s)
Reset Password
Get link
Create New User
- Before creating a new account, please check if you already have an account using the directory search.
- A link will be emailed to you. Please click on it to activate the account.
- All fields are required.
Username must be at least 7 characters long.
Password must be at least 7 characters long and different from your username.
Password must be at least 7 characters long and different from your username.
An email will be sent to this address requiring you to confirm its receipt to activate your account.
What is 800 + 15?
Working
Progress
NextGen Cassava
NextGen Cassava Breeding project promises to substantially increase the rate of genetic improvement in cassava breeding and unlock the full potential of cassava, a staple crop central to food security and livelihoods across Africa.
MoreProject Partners
- College of Agriculture and Life Sciences, Cornell University, USA
- National Crops Resources Research Institute (NaCRRI), Uganda
- National Root Crops Research Institute (NRCRI), Nigeria
- International Institute of Tropical Agriculture (IITA), Nigeria
- Boyce Thompson Institute (BTI) for Plant Research, USA
- US Department of Energy (DOE) Joint Genome Institute (JGI), USA
- Makerere University, Uganda
powered by
Contact